Unleashing the power of generative AI: Verisk’s journey to an Instant Insight Engine for enhanced customer support

This post is co-written with Tom Famularo, Abhay Shah and Nicolette Kontor from Verisk.
Verisk (Nasdaq: VRSK) is a leading data analytics and technology partner for the global insurance industry. Through advanced analytics, software, research, and industry expertise across over 20 countries, Verisk helps build resilience for individuals, communities, and businesses. The company is committed to ethical and responsible AI development, with human oversight and transparency. Verisk is using generative artificial intelligence (AI) to enhance operational efficiencies and profitability for insurance clients while adhering to its ethical AI principles.
Verisk’s FAST platform is a leader in the life insurance and retirement sector, providing enhanced efficiency and flexible, easily upgradable architecture. FAST has earned a fourth consecutive leader ranking in the 2024 ISG Provider Lens report for its seamless integration with Verisk’s data, analytics, and claims tools. The software as a service (SaaS) platform offers out-of-the-box solutions for life, annuity, employee benefits, and institutional annuity providers. With preconfigured components and platform configurability, FAST enables carriers to reduce product time-to-market by 75% and launch new offerings in as little as 2 months.
In this post, we describe the development of the customer support process in FAST incorporating generative AI, the data, the architecture, and the evaluation of the results. Conversational AI assistants are rapidly transforming customer and employee support. Verisk has embraced this technology and has developed their own Instant Insight Engine, or AI companion, that provides an enhanced self-service capability to their FAST platform.
The Opportunity
Verisk FAST’s initial foray into using AI was due to the immense breadth and complexity of the platform. With hundreds of thousands of hours spent on customer support every year, it became abundantly clear they needed help to scale their efforts and meet their objectives. Verisk’s talented teams were overloaded handling common inquiries, leaving less time for the type of innovation that would allow them to maintain the pole position as insurance technology providers.
Verisk FAST’s AI companion aims to alleviate this burden by not only providing 24/7 support for business processing and configuration questions related to FAST, but also tapping into the immense knowledge base to provide an in-depth, tailored response. It is designed to be deeply integrated into the FAST platform and use all of Verisk’s documentation, training materials, and collective expertise. It relies on a Retrieval Augmented Generation (RAG) approach and a mix of AWS services and proprietary configuration to instantly answer most user questions about the Verisk FAST platform’s extensive capabilities.
When the AI companion is rolled out at scale, it will allow Verisk’s staff to focus more time on complex problems, critical initiatives, and innovation while delivering a better customer experience. As part of the build-out, Verisk came across several considerations, key findings, and decisions worth sharing for any enterprise looking to take the first step in tapping into generative AI’s potential.
The Approach
When building an interactive agent with large language models (LLMs), there are often two techniques that can be used: RAG and fine-tuning. The choice between these approaches depends on the use case and available dataset. Verisk FAST started building a RAG pipeline for their AI companion and have iteratively enhanced this solution. The following are some of the reasons why continuing with a RAG architecture made sense to Verisk:
- Access to Dynamic Data – The FAST platform is a constantly evolving platform adding both business functionality and technical capabilities. Verisk needed to make sure their responses were always based on the most up-to-date information. The RAG approach allows for accessing frequently updated data, enabling responses using the most recent information without frequent retraining of the model.
- Multiple Data Sources – In addition to recency of data, another important aspect was the ability to tap into multiple different data sources to retrieve the right context. These data sources may be both internal and external to provide a more holistic response. The ease of expanding the knowledge domain without the need to fine-tune with new data sources makes the solution extensible.
- Reduce Hallucination – Retrieval reduces the risk of hallucination compared to free-form text generation because responses derive directly from the provided excerpts.
- LLM Linguistics – Although appropriate context can be retrieved from enterprise data sources, the underlying LLM handles linguistics and fluency.
- Transparency – Verisk wants to continuously improve the AI companion’s ability to generate responses. A RAG architecture gave them the transparency needed into the context retrieval process, information that would ultimately be used for generating user responses. Having that transparency helped Verisk identify areas of the system where their documents were lacking and needed some restructuring.
- Data governance – With a wide variety of users accessing the platform and with different users having access to different data, data governance and isolation was paramount. Verisk injected controls into the RAG pipeline that restricted access to data based on user access controls, making sure responses were highly tuned to the user.
Although both RAG and fine-tuning have trade-offs, RAG was the optimal approach for building an AI companion on the FAST platform given their requirements for real-time accuracy, explainability, and configurability. The pipeline architecture allows for iterative enhancement as Verisk FAST’s use cases evolve.
Solution Overview
The following diagram presents a high-level architectural data flow highlighting several of the AWS services used in building the solution. Verisk’s solution represents a compound AI system, involving multiple interacting components and making numerous calls to the LLM to furnish responses to the user. Using the FAST platform for orchestrating these diverse components proved to be an intuitive choice, circumventing certain challenges encountered with alternative frameworks such as LangChain.
The key components are as follows:
Amazon Comprehend
To bolster security, Verisk aimed to block the submission of personally identifiable information (PII) within user questions. Although PII isn’t typically necessary for interactions with the AI companion, Verisk employed Amazon Comprehend to detect any potential PII within queries.
Amazon Kendra
In designing an effective RAG solution, one of the most critical steps is the context retrieval from enterprise documentation. Although many options exist to store embeddings, Verisk FAST opted to use Amazon Kendra due to its powerful out-of-the-box semantic search capabilities. As a fully managed service, Verisk took advantage of its deep-learning search models without additional provisioning. Verisk compared using Amazon OpenSearch Serverless with several embedding approaches and Amazon Kendra, and saw better retrieval results with Amazon Kendra. As you’ll see further in the post, Verisk incorporated the Retrieve API and the Query API to retrieve semantically relevant passages for their queries to further improve generation by the LLM.
Amazon Bedrock
Anthropic Claude, available in Amazon Bedrock, played various roles within Verisk’s solution:
- Response Generation – When building their AI companion, Verisk thoroughly evaluated the LLM options from leading providers, using their dataset to test each model’s comprehension and response quality. After this extensive testing, Verisk found Anthropic’s Claude model consistently outperformed across key criteria. Claude demonstrated superior language understanding in Verisk’s complex business domain, allowing more pertinent responses to user questions. It also did exceedingly well at SQL generation, better than any other model they tested. Given Claude’s standout results across Verisk FAST’s use cases, it was the clear choice to power their AI companion’s natural language capabilities.
- Preprocessing of Images and Videos – The outputs from Amazon Rekognition and Amazon Transcribe were fed into Claude. Claude demonstrated remarkable capabilities in generating natural language descriptions, which could be effectively used for indexing purposes with Amazon Kendra. Additionally, Claude excelled at summarizing video transcriptions into concise segments corresponding to specific time intervals, enabling the display of videos at precise points. This combination of AWS services and Claude’s language processing capabilities facilitated a more intuitive and user-friendly experience for media exploration and navigation.
- Relevance Ranking – Although Amazon Kendra returned confidence scores on search results, Verisk needed to further tune the search results for Query API calls for a few scenarios. Verisk was able to use Claude to rank the relevance of search results from Amazon Kendra, further improving the results returned to the user.
- Tool Identification – Verisk used Claude to determine the most suitable techniques, whether API calls or SQL queries, for retrieving data from the operational database based on user requests. Furthermore, Claude generated SQL queries tailored to the provided schemas, enabling efficient data retrieval.
- Conversation Summarization – When a user asks a follow-up question, the AI companion can continue the conversational thread. To enable this, Verisk used Claude to summarize the dialogue to update the context from Amazon Kendra. The full conversation summary and new excerpts are input to the LLM to generate the next response. This conversational flow allows the AI compan to answer user follow-up questions and have a more natural, contextual dialogue, bringing Verisk FAST closer to having a true AI assistant that can engage in useful back-and-forth conversations with users.
Amazon Rekognition
Primarily used for processing images containing text and process flow diagrams, the pre-trained features of Amazon Rekognition facilitated information extraction. The extracted data was then passed to Claude for transformation into a more natural language format suitable for indexing within Amazon Kendra.
Amazon Transcribe
Similar to Amazon Rekognition, Amazon Transcribe was employed to preprocess videos and generate transcripts, with a notable feature being the masking of sensitive information. The verbose transcripts, along with timestamps, were condensed using Claude before being indexed into Amazon Kendra.
Prompt Template Warehouse
Central to the solution was the dynamic selection of templates to create prompts based on question classification. Substantial effort was invested in developing and continuously improving these prompt templates.
Throughout Verisk’s journey, they worked closely with the AWS Solutioning team to brainstorm concrete suggestions to enhance the overall solution.
Data Harvesting
Before Verisk started building anything in the platform, they spent weeks amassing information, initially in the form of questions and answers. Verisk FAST’s initial dataset comprised 10,000 questions and their corresponding answers, meticulously collected and vetted to confirm accuracy and relevance. However, they understood that this was not a one-and-done effort. Verisk needed to continually expand its knowledge base by identifying new data sources across the business.
Driven by this, Verisk diligently added 15,000 more questions, making sure they covered less frequently encountered scenarios. Verisk also added user guides, technical documentation, and other text-based information. This data spanned several categories, from business processing to configuration to their delivery approach. This enriched the AI companion’s knowledge and understanding of diverse user queries, enabling it to provide more accurate and insightful responses.
The Verisk FAST team also recognized the necessity of exploring additional modalities. Videos and images, particularly those illustrating process flows and information sharing videos, proved to be invaluable sources of data. During the initial rollout phase, it became evident that certain inquiries demanded real-time data retrieval from their operational data store. Through some slick prompt engineering and using Claude’s latest capabilities to invoke APIs, Verisk seamlessly accessed their database to procure real-time information.
Structuring and Retrieving the Data
An essential element in developing the AI companion’s knowledge base was properly structuring and effectively querying the data to deliver accurate answers. Verisk explored various techniques to optimize both the organization of the content and the methods to extract the most relevant information:
- Chunking – One key step in preparing the accumulated questions and answers was splitting the data into individual documents to facilitate indexing into Amazon Kendra. Rather than uploading a single large file containing all 10,000 question-answer pairs, Verisk chunked the data into 10,000 separate text documents, with each document containing one question-answer pair. By splitting the data into small, modular documents focused on a single question-answer pair, Verisk could more easily index each document and had greater success in pulling back the correct context. Chunking the data also enabled straightforward updating and reindexing of the knowledge base over time. Verisk applied the same technique to other data sources as well.
- Selecting the Right Number of Results – Verisk tested configuring Amazon Kendra to return different numbers of results for each question query. Returning too few results ran the risk of not capturing the best answer, whereas too many results made it more difficult to identify the right response. Verisk found returning the top three matching results from Amazon Kendra optimized both accuracy and performance.
- Multi-step Query – To further improve accuracy, Verisk implemented a multi-step query process. First, they used the Amazon Kendra Retrieve API to get multiple relevant passages and excerpts based on keyword search. Next, they took a second pass at getting excerpts through the Query API, to find any additional shorter documents that might have been missed. Combining these two query types enabled Verisk to reliably identify the correct documentation and excerpts to generate a response.
- Relevance Parameters – Verisk also tuned relevance parameters in Amazon Kendra to weigh their most up-to-date documentation higher than others. This improved results over just generic text search.
By thoroughly experimenting and optimizing both the knowledge base powering their AI companion and the queries to extract answers from it, Verisk was able to achieve very high answer accuracy during the proof of concept, paving the way for further development. The techniques they explored—multi-stage querying, tuning relevance, enriching data—became core elements of their approach for extracting quality automated answers.
LLM Parameters and Models
Experimenting with prompt structure, length, temperature, role-playing, and context was key to improving the quality and accuracy of the AI companion’s Claude-powered responses. The prompt design guidelines provided by Anthropic were incredibly helpful.
Verisk crafted prompts that provided Claude with clear context and set roles for answering user questions. Setting the temperature to 0.5 helped reduce randomness and repetition in the generated responses.
Verisk also experimented with different models to improve the efficiency of the overall solution. Although Claude 3 models like Sonnet and Haiku did a great job at generating responses, as part of the overall solution, Verisk didn’t always need the LLM to generate text. For scenarios that required identification of tools, Claude Instant was a better suited model due to its quicker response times.
Metrics, Data Governance, and Accuracy
A critical component of Verisk FAST’s AI companion and its usefulness is their rigorous evaluation of its performance and the accuracy of its generated responses.
As part of the proof of concept in working with the Amazon Generative AI Innovation Center, Verisk came up with 100 questions to evaluate the accuracy and performance of the AI companion. Central to this process was crafting questions designed to assess the bot’s ability to comprehend and respond effectively across a diverse range of topics and scenarios. These questions spanned a variety of topics and varying levels of difficulty. Verisk wanted to make sure their AI companion provided accurate responses to frequently asked questions and could demonstrate proficiency in handling nuanced and less predictable or straightforward inquiries. The results provided invaluable insights into RAG’s strengths and areas for improvement, guiding Verisk’s future efforts to refine and enhance its capabilities further.
After Verisk integrated their AI companion into the platform and began testing it with real-world scenarios, their accuracy rate was approximately 40%. However, within a few months, it rapidly increased to over 70% because of all the data harvesting work, and the accuracy continues to steadily improve each day.
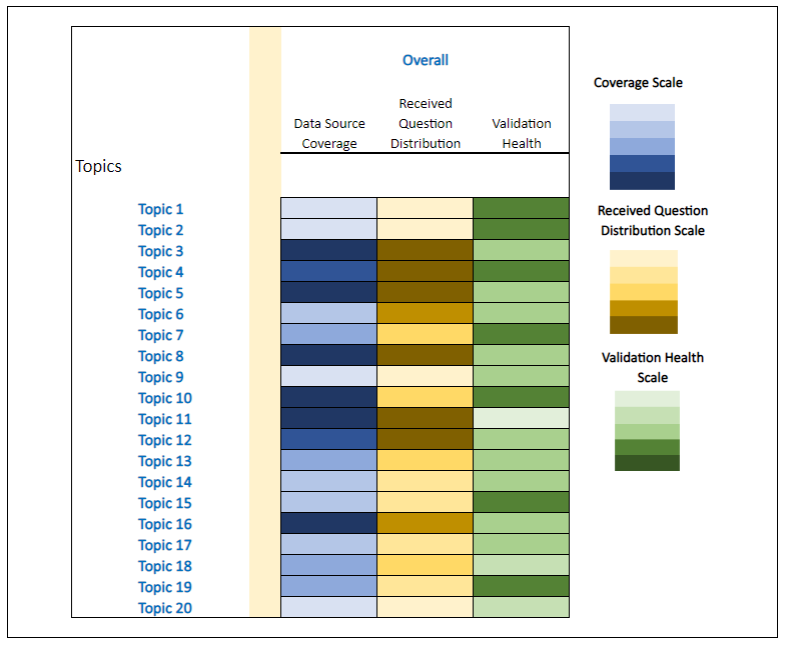
Contributing to the AI companion’s rising accuracy is Verisk’s evaluation heat map. This provides a visual representation of the documentation available across 20 topics that comprehensively encompasses the Verisk FAST platform’s capabilities. This is compared against the volume of inquiries within each specific topic segment and the health of the generated responses in each.
This visualized data allows the Verisk FAST team to effortlessly identify gaps. They can quickly see which capability the AI companion currently struggles with against where user questions are most focused on. The Verisk team can then prioritize expanding its knowledge in these areas through additional documentation, training data, research materials, and testing.
Business Impact
Verisk initially rolled out the AI companion to one beta customer to demonstrate real-world performance and impact. Supporting a customer in this way is a stark contrast to how Verisk has historically engaged with and supported customers in the past, where they would typically have a team allocated to interact with the customer directly. Now only a fraction of the time a person would usually spend is needed to review submissions and adjust responses. Verisk FAST’s AI companion has helped them cost-effectively scale while still providing high-quality assistance.
In analyzing this early usage data, Verisk uncovered additional areas they can drive business value for their customers. As they collect additional information, this data will help them uncover what will be needed to improve results and prepare for a wider rollout.
Ongoing development will focus on expanding these capabilities, prioritized based on the collected questions. Most exciting, though, are the new possibilities on the horizon with generative AI. Verisk knows this technology is rapidly advancing, and they are eager to harness innovations to bring even more value to their customers. As new models and techniques emerge, Verisk plans to adapt their AI companion to take advantage of the latest capabilities. Although the AI companion currently focuses on responding to user questions, this is only the starting point. Verisk plans to quickly improve its capabilities to proactively make suggestions and configure functionality directly in the system itself. The Verisk FAST team is inspired by the challenge of pushing the boundaries of what is possible with generative AI and is excited to test the limits of what’s possible.
Conclusion
Verisk’s journey in developing an AI companion for their FAST platform showcases the immense potential of generative AI to transform customer support and drive operational efficiencies. By meticulously harvesting, structuring, and retrieving data, and leveraging large language models, semantic search capabilities, and rigorous evaluation processes, Verisk has created a robust solution that provides accurate, real-time responses to user inquiries. As Verisk continues to expand the AI companion’s capabilities while adhering to ethical and responsible AI development practices, they are poised to unlock greater value for customers, enable staff to focus on innovation, and set new standards for customer support in the insurance industry.
For more information, see the following resources:
About the Authors
 Tom Famularo was Co-Founder/CEO or FAST and lead’s Verisk Life Solutions, based in NJ. Tom is responsible for platform strategy, data/analytics, AI and Verisk’s life/annuity customers. His focus and passion are for teaching customers and team members how to allow technology to enable business outcomes with far less human effort. Outside of work, he’s an avid fan of his son’s baseball and football teams.
Tom Famularo was Co-Founder/CEO or FAST and lead’s Verisk Life Solutions, based in NJ. Tom is responsible for platform strategy, data/analytics, AI and Verisk’s life/annuity customers. His focus and passion are for teaching customers and team members how to allow technology to enable business outcomes with far less human effort. Outside of work, he’s an avid fan of his son’s baseball and football teams.
 Abhay Shah leads engineering efforts for the FAST Platform at Verisk – Life Solutions, where he offers guidance on architecture and provides technical leadership for Customer Implementations and Product Development. With over two decades of experience in the technology sector, Abhay helps insurance carriers maximize the value of their ecosystem through modern technology and is excited by the opportunities that AI provides. Beyond his professional passion, he enjoys reading, traveling, and coaching the middle school robotics team.
Abhay Shah leads engineering efforts for the FAST Platform at Verisk – Life Solutions, where he offers guidance on architecture and provides technical leadership for Customer Implementations and Product Development. With over two decades of experience in the technology sector, Abhay helps insurance carriers maximize the value of their ecosystem through modern technology and is excited by the opportunities that AI provides. Beyond his professional passion, he enjoys reading, traveling, and coaching the middle school robotics team.
 Nicolette Kontor is a technology enthusiast who thrives on helping customers embrace digital transformation. In her current role at Verisk – Life Solutions, she spearheads the application of artificial intelligence to the FAST Platform, which she finds tremendously rewarding and exciting. With over 10 years of experience in major customer implementations and product development, Nicolette is driven to deliver innovative solutions that unlock value for insurance carriers. Beyond her professional pursuits, Nicolette is an avid traveler, having explored 39 countries to date. She enjoys winning trivia, reading mystery novels, and learning new languages.
Nicolette Kontor is a technology enthusiast who thrives on helping customers embrace digital transformation. In her current role at Verisk – Life Solutions, she spearheads the application of artificial intelligence to the FAST Platform, which she finds tremendously rewarding and exciting. With over 10 years of experience in major customer implementations and product development, Nicolette is driven to deliver innovative solutions that unlock value for insurance carriers. Beyond her professional pursuits, Nicolette is an avid traveler, having explored 39 countries to date. She enjoys winning trivia, reading mystery novels, and learning new languages.
 Ryan Doty is a Sr. Solutions Architect at AWS, based out of New York. He helps enterprise customers in the Northeast U.S. accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
Ryan Doty is a Sr. Solutions Architect at AWS, based out of New York. He helps enterprise customers in the Northeast U.S. accelerate their adoption of the AWS Cloud by providing architectural guidelines to design innovative and scalable solutions. Coming from a software development and sales engineering background, the possibilities that the cloud can bring to the world excite him.
 Tarik Makota is a Senior Principal Solutions Architect with Amazon Web Services. He provides technical guidance, design advice, and thought leadership to AWS’ customers across the US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
Tarik Makota is a Senior Principal Solutions Architect with Amazon Web Services. He provides technical guidance, design advice, and thought leadership to AWS’ customers across the US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
 Dom Bavaro is a Senior Solutions Architect for Financial Services. While providing technical guidance to customers across many use cases, He is focused on helping customer build and productionize Generative AI solutions and workflows
Dom Bavaro is a Senior Solutions Architect for Financial Services. While providing technical guidance to customers across many use cases, He is focused on helping customer build and productionize Generative AI solutions and workflows



