Empowering Developers to Harness Sensor Data for Advanced Analytics

Data from sensors offers a treasure trove of insights from the physical world for data scientists. From tracking temperature fluctuations in a greenhouse to analyzing the vibrations of industrial machines in a manufacturing plant, these tiny devices capture crucial information that can be used for groundbreaking research and development. The journey from collecting raw sensor data to actionable analysis can be riddled with stumbling blocks, as the realities of hardware components and environmental conditions come into play.
The typical approach to sensor data capture often involves a cumbersome workflow across the various teams involved, including data scientists and engineers. While data scientists meticulously define sensor requirements and prepare their notebooks to process the information, engineers deal with the complexities of hardware deployment and software updates that reduce the scientists’ ability to quickly adjust these variables on the fly. This creates a long feedback loop that delays the pace of innovation across the organization.
I have observed a few areas where this process can be improved:
- Device deployments
- Observability and updates
- Security and resiliency
Imagine a world where the folks reliant upon sensor data hold the reins when it comes to gathering it from those devices in the field. No more waiting on other teams (who have their own backlog of work) for basic configurations or deployment queues hindering exploration. By streamlining the process and reducing the various barriers of entry, data teams could have more information and experiments to efficiently improve their work.
To demonstrate how we can improve in those key areas, I’m going to use Viam to set up a smart machine to capture movement sensor data I’m gathering to analyze the working conditions of my home laundry machines, which have been encountering issues as they age. Viam is a platform that helps close the gap between hardware and software with its cloud services and open source software.
Repeatable Device Deployments
While access to Linux single-board computers and Arduino-compatible microcontrollers has become easier than ever, enabling many more people to start controlling hardware; there is still a learning curve for creating a reliable program that will work across those target devices.
For my project, I chose a Raspberry Pi 4B that I already had on hand and an MPU-6050 combination gyroscope and accelerometer breakout sensor to get several varying data points. With Raspbian (the Raspberry Pi distribution of Debian) already running on my Pi and already having it connected to my local network, I created a new machine in Viam and installed viam-server with my connection configuration following the documentation. With my Pi connected to Viam, I wired up my movement sensor to the main I2C pins and added the movement sensor to the machine configuration in the app. Now the device is ready to be deployed to my laundry room and start capturing sensor data!
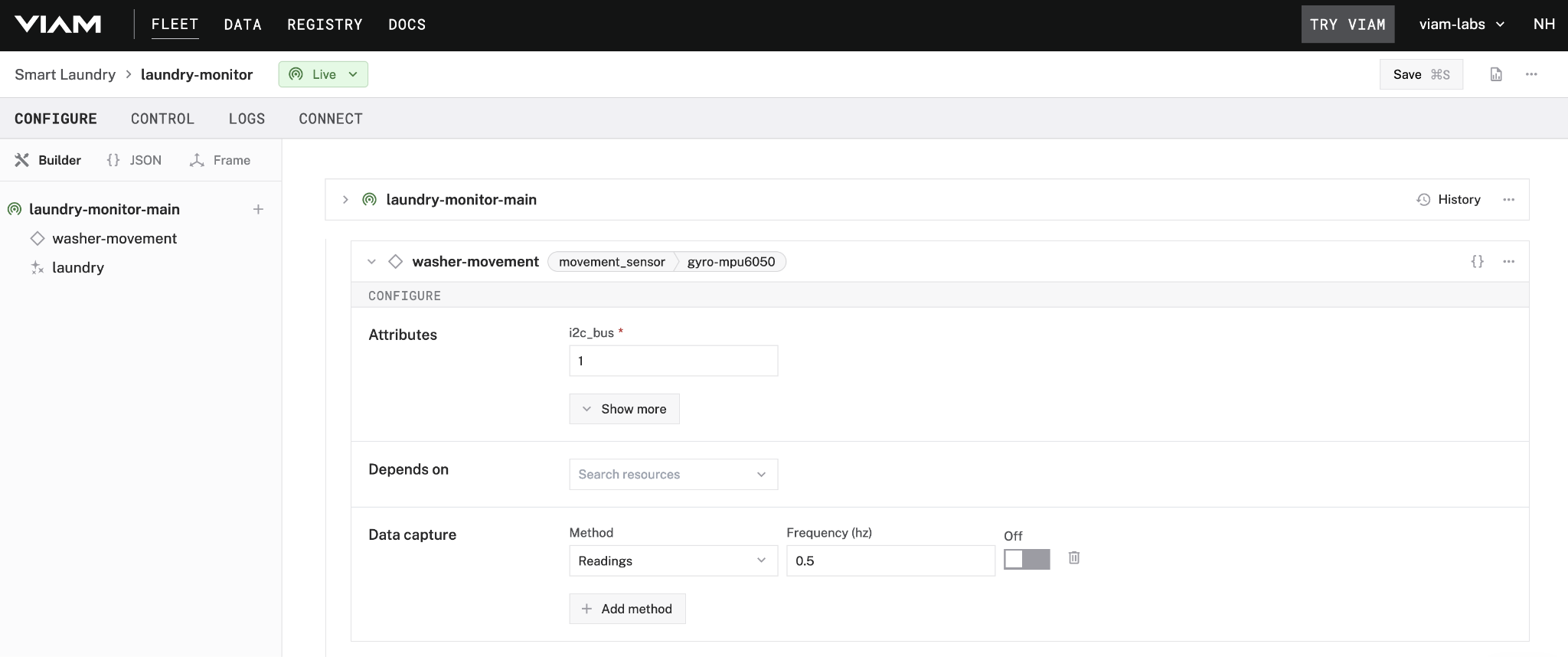
Even as someone with hardware programming experience, it’s hard to beat the accessibility of this workflow. If I need to replace the board, I can install viam-server and the connection config to the new computer and be back in business in no time. If I needed to scale this out to several more machines to generalize my dataset, I could create a reusable configuration fragment as a single source of truth across my personal fleet.
Remote Monitoring and Updates for Sensor Components
As mentioned previously, data teams tend to see the results of the data capture process once it has been pooled together rather than at the source. If there’s any issue with that source, like hardware defects with sensor or tampering in the environment, the team won’t know until the garbage information has affected the rest of the dataset and may have no access to shut it off until a partner engineering team has the bandwidth to help.
After setting up the Pi and sensor on the offending washer, I want to check out the type of readings emitted from the hardware. From the Control tab of the app, I can see the values streaming in along with some other details about the status of my machine. I can move around the placement of the sensor to see how that affects the readings before settling on the long-term position.
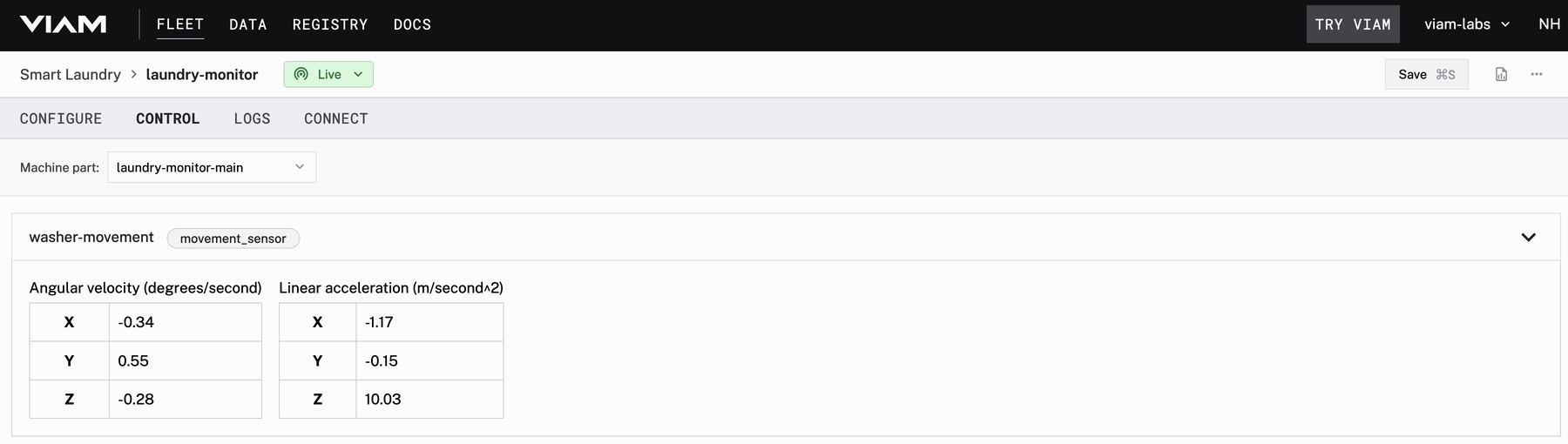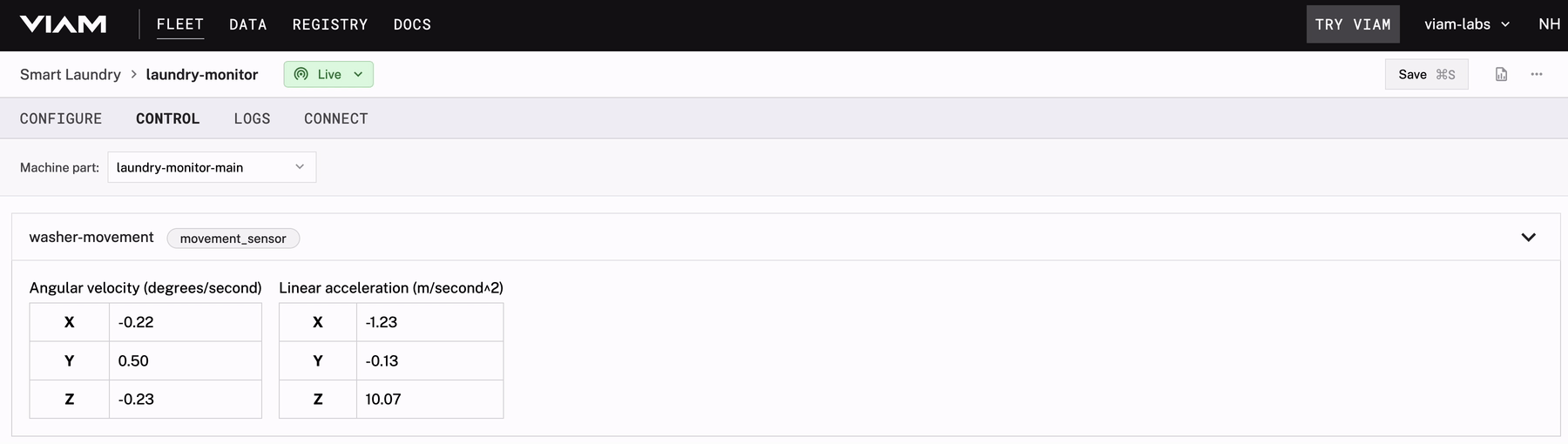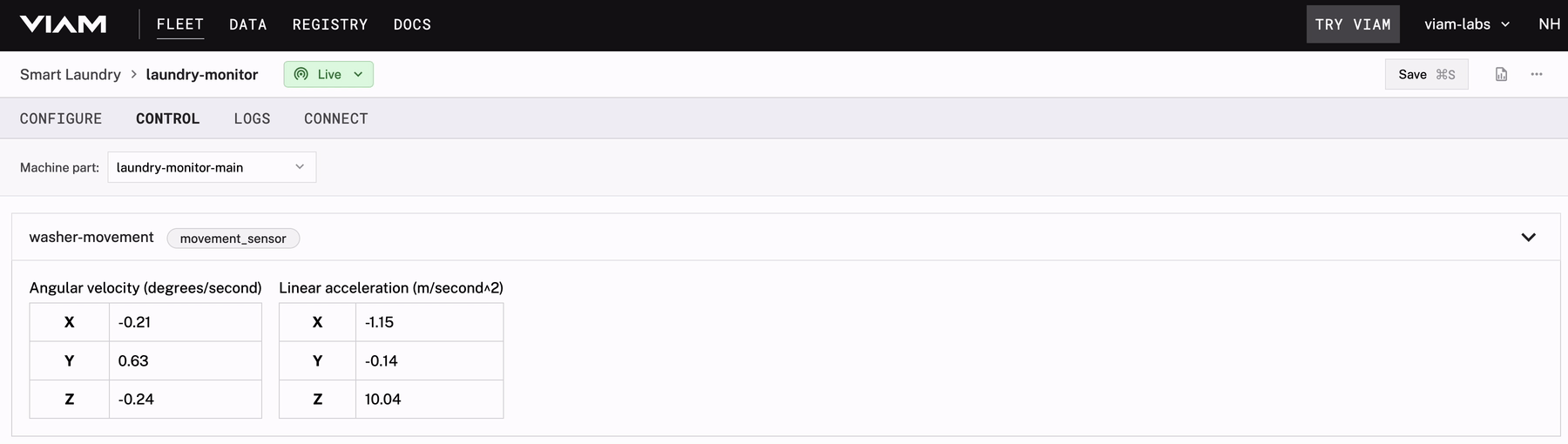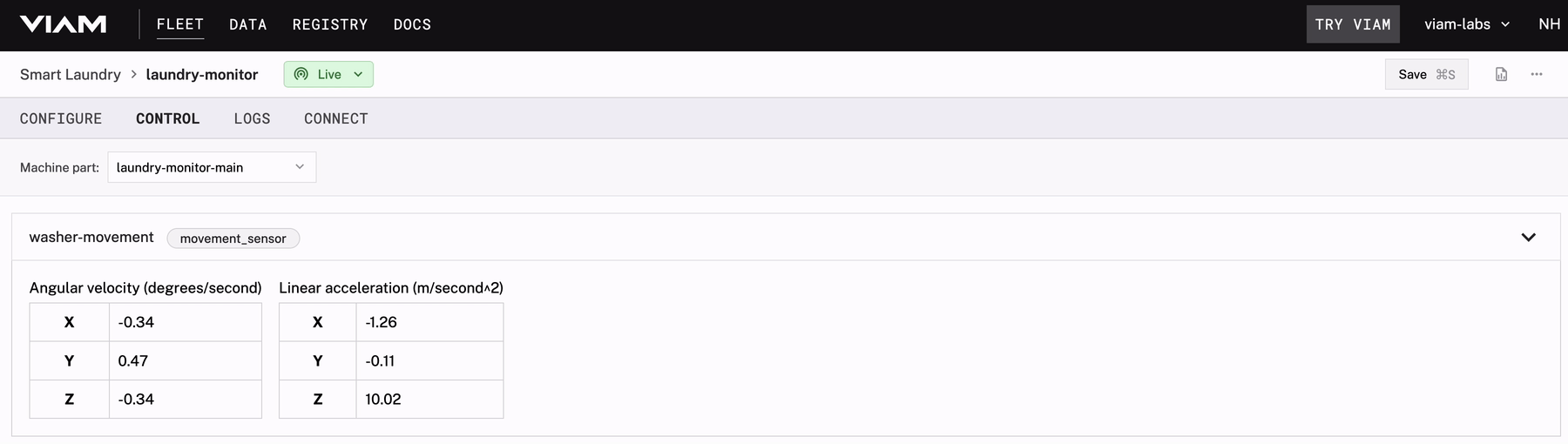
As I start to learn the baseline of expected values during different stages of the life cycle, I can monitor the sensor health through this remote dashboard or the Viam mobile app while on the go.
Now that I have a good idea of the data that I’ll get from the sensor, I want to start actually saving it for later analysis and experiments. I added the Viam data management service to my machine configuration, that will allow me to control where the sensor data should be stored on the device, various tags to apply to the data, and how often to sync it to the cloud.
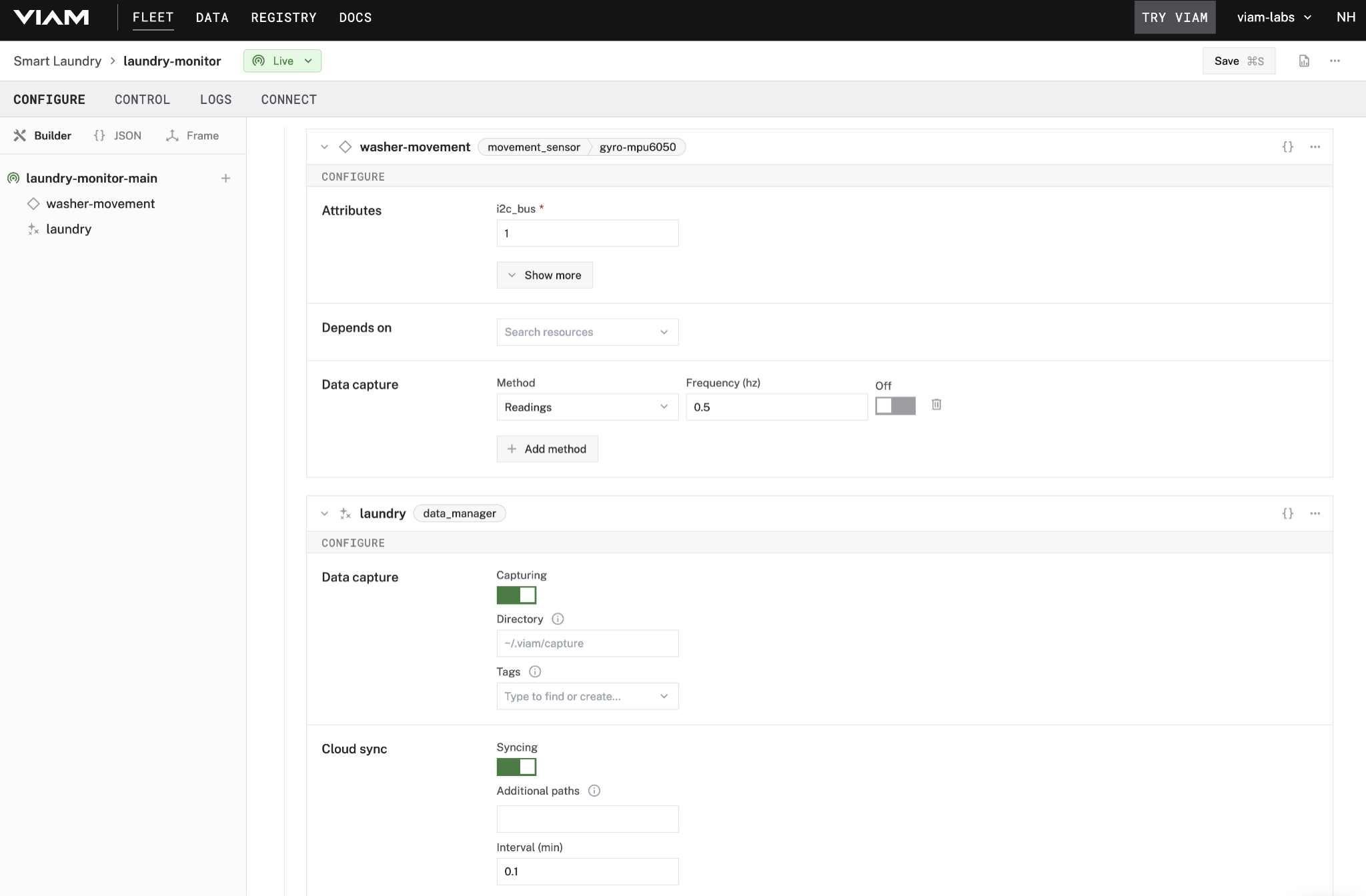
With that in place, I can update my sensor configuration to capture the values that I care about and the frequency at which to get those values. With the movement sensor, which actually contains a few individual sensors (gyroscope, accelerometer, temperature), I can choose to lump all the readings together or break them out as individual records when they sync to the cloud service. Since I’m not sure how I’ll use this data yet, I’m going to get all the readings together; if I find that I only need a subset of information, then I can update the configuration later to save on storage.
This sort of flexibility and control puts the power in my hands to optimize my data requirements without working around other teams. If I know there’s some environmental condition like moving the laundry machines for maintenance or a storm that will impact how they operate, I can toggle off the data capture without affecting the rest of the set.
Secure and Resilient Syncing of Data Across Network Conditions
In order to collect sensor data, services require the data to be sent over as it is collected regardless of network status or reliability. This will lead to missed data or extra processing required to handle flakey and offline device connections; pretty hard to be an IoT device without the internet.
For my project, even my home does not have 100% uptime; whether my ISP has an incident or I’m reconfiguring my routers and access points, the devices on my local network need to be able to go offline occasionally. This resiliency is built-into the data management service I added to my machine configuration already. If the Raspberry Pi loses its connection or the network becomes unstable, the data will continue to be captured to the local filesystem until the service can successfully sync again before clearing the cached data. Even if the device is taken out of commission entirely, I know I can find that data on the device for manual upload if needed.
If the device suddenly restarts due to a power outage during the middle of a sync, I know I can rely on the data manager to resolve that interruption once it comes back online without sending duplicate data that I would need to clear from my dataset later.
While losing data for my project wouldn’t be the end of the world, there’s comfort in knowing these same considerations would be in place for any future work that had higher consistency requirements.
Create Smarter Data Sensor Data Pipelines
As you plan your next big initiative based on hardware feedback out in the real world, think about those factors that will impact its success.
- How quickly can you deploy and iterate on those devices?
- How much control do you have as a data team to manage the type and amount of information being collected?
- Will those sensors be quick to recover from the instability of the environment in which they’re placed?
I’ve just started my journey into data science and machine learning, but I’m ensuring I have all the right tools to help me along the way.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTube
channel to stream all our podcasts, interviews, demos, and more.




 Assessment 2024 | State")