Improving air quality with generative AI

As of this writing, Ghana ranks as the 27th most polluted country in the world, facing significant challenges due to air pollution. Recognizing the crucial role of air quality monitoring, many African countries, including Ghana, are adopting low-cost air quality sensors.
The Sensor Evaluation and Training Centre for West Africa (Afri-SET), aims to use technology to address these challenges. Afri-SET engages with air quality sensor manufacturers, providing crucial evaluations tailored to the African context. Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management.
On December 6th-8th 2023, the non-profit organization, Tech to the Rescue, in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. More than 170 tech teams used the latest cloud, machine learning and artificial intelligence technologies to build 33 solutions. The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors. The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
Current challenges
Afri-SET currently merges data from numerous sources, employing a bespoke approach for each of the sensor manufacturers. This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration. The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for data ingestion.
The objective is to automate data integration from various sensor manufacturers for Accra, Ghana, paving the way for scalability across West Africa. Despite the challenges, Afri-SET, with limited resources, envisions a comprehensive data management solution for stakeholders seeking sensor hosting on their platform, aiming to deliver accurate data from low-cost sensors. The attempt is disadvantaged by the current focus on data cleaning, diverting valuable skills away from building ML models for sensor calibration. Additionally, they aim to report corrected data from low-cost sensors, which requires information beyond specific pollutants.
The solution had the following requirements:
- Cloud hosting – The solution must reside on the cloud, ensuring scalability and accessibility.
- Automated data ingestion – An automated system is essential for recognizing and synchronizing new (unseen), diverse data formats with minimal human intervention.
- Format flexibility – The solution should accommodate both CSV and JSON inputs and be flexible on the formatting (any reasonable column names, units of measure, any nested structure, or malformed CSV such as missing columns or extra columns)
- Golden copy preservation – Retaining an untouched copy of the data is imperative for reference and validation purposes.
- Cost-effective – The solution should only invoke LLM to generate reusable code on an as-needed basis instead of manipulating the data directly to be as cost-effective as possible.
The goal was to build a one-click solution that takes different data structure and formats (CSV and JSON) and automatically converts them to be integrated into a database with unified headers, as shown in the following figure. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Figure 1: Covert data with different data formats into a desired data format with unified headers
Overview of solution
The proposed solution uses Anthropic’s Claude 2.1 foundation model through Amazon Bedrock to generate Python codes, which converts input data into a unified data format. LLMs excel at writing code and reasoning over text, but tend to not perform as well when interacting directly with time-series data. In this solution, we leverage the reasoning and coding abilities of LLMs for creating reusable Extract, Transform, Load (ETL), which transforms sensor data files that do not conform to a universal standard to be stored together for downstream calibration and analysis. Additionally, we take advantage of the reasoning capabilities of LLMs to understand what the labels mean in the context of air quality sensor, such as particulate matter (PM), relative humidity, temperature, etc.
The following diagram shows the conceptual architecture:

Figure 2: The AWS reference architecture and the workflow for data transformation with Amazon Bedrock
Solution walkthrough
The solution reads raw data files (CSV and JSON files) from Amazon Simple Storage Service (Amazon S3) (Step 1) and checks if it has seen the device type (or data format) before. If yes, the solution retrieves and executes the previously-generated python codes (Step 2) and the transformed data is stored in S3 (Step 10). The solution only invokes the LLM for new device data file type (code has not yet been generated). This is done to optimize performance and minimize cost of LLM invocation. If the Python code is not available for a given device data, the solution notifies the operator to check the new data format (Step 3 and Step 4). At this time, the operator checks the new data format and validates if the new data format is from a new manufacturer (Step 5). Further, the solution checks if the file is CSV or JSON. If it is a CSV file, the data can be directly converted to a Pandas data frame by a Python function without LLM invocation. If it is a JSON file, the LLM is invoked to generate a Python function that creates a Pandas data frame from the JSON payload considering its schema and how nested it is (Step 6).
We invoke the LLM to generate Python functions that manipulate the data with three different prompts (input string):
- The first invocation (Step 6) generates a Python function that converts a JSON file to a Pandas data frame. JSON files from manufacturers have different schemas. Some input data uses a pair of value type and value for a measurement. The latter format results in data frames containing one column of value type and one column of value. Such columns need to be pivoted.
- The second invocation (Step 7) determines if the data needs to be pivoted and generates a Python function for pivoting if needed. Another issue of the input data is that the same air quality measurement can have different names from different manufacturers; for example, “P1” and “PM1” are for the same type of measurement.
- The third invocation (Step 8) focuses on data cleaning. It generates a Python function to convert data frames to a common data format. The Python function may include steps for unifying column names for the same type of measurement and dropping columns.
All LLM generated Python codes are stored in the repository (Step 9) so that this can be used to process daily raw device data files for transformation into a common format.
The data is then stored in Amazon S3 (Step 10) and can be published to OpenAQ so other organizations can use the calibrated air quality data.
The following screenshot shows the proposed frontend for illustrative purposes only as the solution is designed to integrate with Afri-SET’s existing backend system
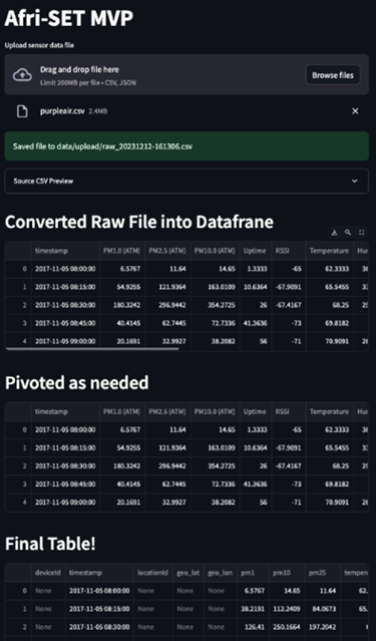
Results
The proposed method minimizes LLM invocations, thus optimizing cost and resources. The solution only invokes the LLM when a new data format is detected. The code that is generated is stored, so that an input data with the same format (seen before) can reuse the code for data processing.
A human-in-the-loop mechanism safeguards data ingestion. This happens only when a new data format is detected to avoid overburdening scarce Afri-SET resources. Having a human-in-the-loop to validate each data transformation step is optional.
Automatic code generation reduces data engineering work from months to days. Afri-SET can use this solution to automatically generate Python code, based on the format of input data. The output data is transformed to a standardized format and stored in a single location in Amazon S3 in Parquet format, a columnar and efficient storage format. If useful, it can be further extended to a data lake platform that uses AWS Glue (a serverless data integration service for data preparation) and Amazon Athena (a serverless and interactive analytics service) to analyze and visualize data. With AWS Glue custom connectors, it’s effortless to transfer data between Amazon S3 and other applications. Additionally, this is a no-code experience for Afri-SET’s software engineer to effortlessly build their data pipelines.
Conclusion
This solution allows for easy data integration to help expand cost-effective air quality monitoring. It offers data-driven and informed legislation, fostering community empowerment and encouraging innovation.
This initiative, aimed at gathering precise data, is a significant step towards a cleaner and healthier environment. We believe that AWS technology can help address poor air quality through technical solutions similar to the one described here. If you want to prototype similar solutions, apply to the AWS Health Equity initiative.
As always, AWS welcomes your feedback. Please leave your thoughts and questions in the comments section.
About the authors
 Sandra Topic is an Environmental Equity Leader at AWS. In this role, she leverages her engineering background to find new ways to use technology for solving the world’s “To Do list” and drive positive social impact. Sandra’s journey includes social entrepreneurship and leading sustainability and AI efforts in tech companies.
Sandra Topic is an Environmental Equity Leader at AWS. In this role, she leverages her engineering background to find new ways to use technology for solving the world’s “To Do list” and drive positive social impact. Sandra’s journey includes social entrepreneurship and leading sustainability and AI efforts in tech companies.
 Qiong (Jo) Zhang, PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML. Her current areas of interest include federated learning, distributed training, and generative AI. She holds 30+ patents and has co-authored 100+ journal/conference papers. She is also the recipient of the Best Paper Award at IEEE NetSoft 2016, IEEE ICC 2011, ONDM 2010, and IEEE GLOBECOM 2005.
Qiong (Jo) Zhang, PhD, is a Senior Partner Solutions Architect at AWS, specializing in AI/ML. Her current areas of interest include federated learning, distributed training, and generative AI. She holds 30+ patents and has co-authored 100+ journal/conference papers. She is also the recipient of the Best Paper Award at IEEE NetSoft 2016, IEEE ICC 2011, ONDM 2010, and IEEE GLOBECOM 2005.
 Gabriel Verreault is a Senior Partner Solutions Architect at AWS for the Industrial Manufacturing segment. Gabriel works with AWS partners to define, build, and evangelize solutions around Smart Manufacturing, Sustainability and AI/ML. Gabriel also has expertise in industrial data platforms, predictive maintenance, and combining AI/ML with industrial workloads.
Gabriel Verreault is a Senior Partner Solutions Architect at AWS for the Industrial Manufacturing segment. Gabriel works with AWS partners to define, build, and evangelize solutions around Smart Manufacturing, Sustainability and AI/ML. Gabriel also has expertise in industrial data platforms, predictive maintenance, and combining AI/ML with industrial workloads.
 Venkatavaradhan (Venkat) Viswanathan is a Global Partner Solutions Architect at Amazon Web Services. Venkat is a Technology Strategy Leader in Data, AI, ML, generative AI, and Advanced Analytics. Venkat is a Global SME for Databricks and helps AWS customers design, build, secure, and optimize Databricks workloads on AWS.
Venkatavaradhan (Venkat) Viswanathan is a Global Partner Solutions Architect at Amazon Web Services. Venkat is a Technology Strategy Leader in Data, AI, ML, generative AI, and Advanced Analytics. Venkat is a Global SME for Databricks and helps AWS customers design, build, secure, and optimize Databricks workloads on AWS.



