Is LLM Training Data Running Out?

- AI model training is a rapidly growing and highly capital-, compute-, power-, and data-intensive process.
- Funds can be procured, computing is advancing at full speed, power generation can be sourced through cleaner methods, and AI talent is rapidly emerging.
- However, sourcing publicly available data will be a major problem for AI companies at the turn of the decade.
- How can companies ensure AI development doesn’t stall?
According to Stanford University’s AI Index Report 2024, the United States produced 61 noteworthy machine learning models in 2023, followed by China’s 15, France’s eight, Germany’s five, and Canada’s four. In the same year, 149 foundation models were released globally.
The rapid pace of development has spilled into 2024, with the industry setting unprecedented expectations and delivering innovation, growth, and higher integration.
Financially, training a single large language model (LLM) costs tens of millions of dollars. For instance, OpenAI CEO Sam Altman said the company spent over $100 million to train GPT-4. Google spent an estimated $191 million on computing to train Gemini Ultra. Having deep pockets and a propensity to splurge helps.
The demand for AI computing power is doubling every 100 days, according to Intelligent Computing: The Latest Advances, Challenges, and Future research. It is projected to increase over a million times over the next five years. “With the slowing down of Moore’s law, it becomes challenging to keep up with such a rapid increase in computational capacity requirements,” the authors noted. NVIDIA and other chipmakers are on it.
Further, energy-guzzling LLM training may have alternative solutions. One example is Microsoft planning to build a small-scale reactor to replace fossil fuels for its data center and computing needs, hiring a director of nuclear tech to oversee its plans, and signing an agreement to source power from Helion Energy and its nuclear fusion tech.
Meanwhile, the demand for AI talent in the U.S. almost doubled from 8,611 in May 2023 to over 16,000 in May 2024, according to UMD-LinkUp AI Maps. Fortunately, that’s taking care of itself, as LinkedIn’s Global Talent Trends survey discovered.
The survey noted 17% higher application growth in the past two years in job posts that mention artificial intelligence or generative AI than in job posts with no such mentions. Additionally, 57% of professionals responded positively toward learning more about AI.
What is unclear is how AI companies plan to keep up with the rising demand for data, the building blocks of an LLM’s consciousness, so to speak.
See More: Will Prompt Engineering Change What It Means to Code?
Data Requirements for LLM Training
Let’s look at some numbers:
|
LLM |
Tokens | Release Date |
|---|---|---|
| GPT 2 | ~10 billion |
June 2018 |
|
GPT 3 |
~300 billion | Feb 2019 |
| Claude | ~400 billion |
Dec 2021 |
|
Gopher |
~300 billion | Dec 2021 |
| LaMDA | 168 billion |
Jan 2022 |
|
PaLM |
~780 billion | April 2022 |
| Llama | 1.4 trillion |
Feb 2023 |
|
GPT-4 |
~13 trillion | Mar 2023 |
| PaLM 2 | 3.6 trillion |
May 2023 |
|
Llama 2 |
2 trillion | Jul 2023 |
| Claude 2 | NA |
Jul 2023 |
|
Grok-1 |
NA | Nov 2023 |
| Gemini 1.0 | NA |
Dec 2023 |
|
Claude 3 |
NA | Mar 2024 |
| Llama 3 | NA |
April 2024 |
|
Gemini 1.5 Pro |
NA | May 2024 |
| GPT-4o | NA |
May 2024 |
Since companies have started withholding the training data size, consider the first ten models on the above list. Here’s how steep the rise is when it comes to using training data:
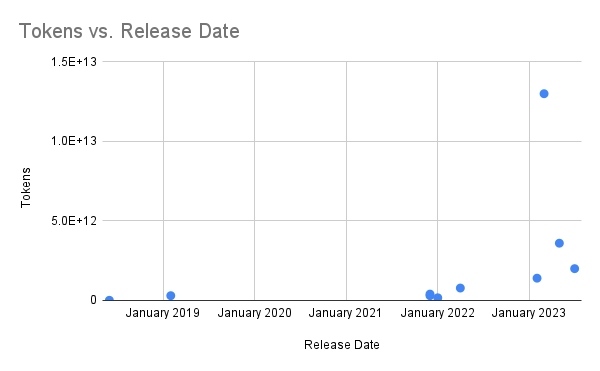
Tokens Used for LLM Training Over The Years
So far, an exponentially higher data ingestion rate for LLM training has been the primary vector of progress. Experts predict this cannot be sustainable over the long term.
See More: AI Benchmarks: Why GenAI Scoreboards Need an Overhaul
Are Companies Running Out of Training Data?
Research suggests that data scarcity is indeed a possibility for LLM training shortly. According to trends analyzed by Epoch AI, tech companies will exhaust publicly available data for LLM training between 2026 and 2032.
“The exact point in time at which this data would be fully utilized depends on how models are scaled. If models are trained compute-optimally, there is enough data to train a model with 5e28 floating-point operations (FLOP), a level we expect to be reached in 2028. But recent models, like Llama 3, are often ‘overtrained’ with fewer parameters and more data to make them more compute-efficient during inference,” Epoch AI researchers noted.
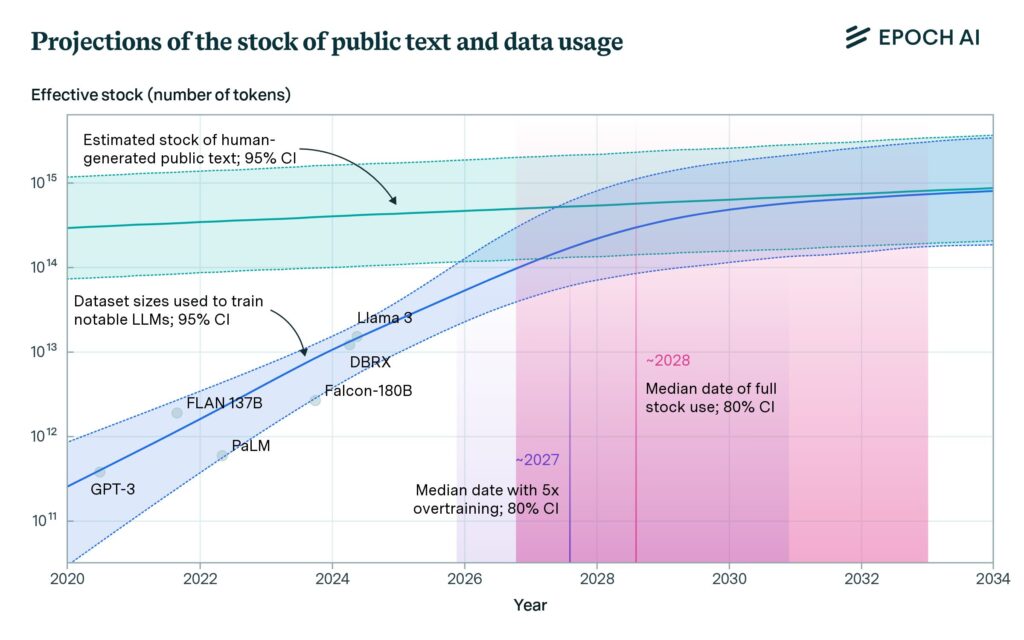
Source: Will we run out of data? Limits of LLM scaling based on human-generated data study by Epoch AI
The crucial thing to note here is that in approximately a decade of generative AI’s existence, companies will have depleted freely available human-generated information in the form of articles, blogs, social media discussions, papers, etc. This rate of data ingestion in LLM training is thus considerably higher than the rate at which humans are producing data.
Moreover, tokens from multiple modalities (text, image, audio, video) for LLM training are also not enough as current video and image stocks are not large enough to prevent a data bottleneck, per the research. Here’s how many tokens each data modality corresponds to:
- Common Crawl: 130 trillion
- Indexed web: 510 trillion
- The whole web: 3100 trillion
- Images: 300 trillion
- Video: 1350 trillion
Publicly available data scraped from the web forms the bedrock of LLM training, but is the situation dire (for AI companies)?
See More: GenAI in Legal Industry: Why Intelligent Document Processing Matters?
How Can AI Companies Scale LLMs Without Public Data?
Experts have advised overcoming the data scarcity problem through multiple methods involving offline information, synthetic data, and LLM efficiency improvements.
1. Cut deals with publishers for non-public data
Paywalled and non-indexed data can be leveraged to train LLMs, provided they are appropriately compensated for respective copyrights.
Content licensing is already a multi-million dollar reality since Google joined hands with Reddit for its data for $60 million. Similarly, OpenAI has signed deals with the Associated Press, Axel Springer, Le Monde, Prisa Medi, and Financial Times.
Offline information, such as books, manuscripts, magazines, etc., can be digitized and licensed for the correct fee.
Moreover, research data, including genomics, financial, scientific databases, etc., can be high-quality data in the right context.
Finally, non-indexed deep web data from social media (Facebook, Instagram, Twitter) and other sources and instant messengers remain untapped. Unfortunately, the former can be lower quality than web data, while the latter violates user privacy.
2. LLM advancements
Refining LLM architecture to consume less data to produce the same result can help contain unchecked data ingestion. Techniques such as reinforcement learning have helped attain sample efficiency gains.
Additionally, data enriching and high-quality sample filtering optimize Pareto efficiency, leading to higher LLM performance and training efficiency improvements, according to findings in the How to Train Data-Efficient LLMs study. Beyond quality, data coverage and diversity also play an important role in making LLMs efficient.
“It’s important to note that the relationship between data quantity and language model performance is not always linear. In some cases, doubling the training data may yield diminishing returns in metrics like perplexity or downstream task accuracy,” noted Sunil Ramlochan, enterprise AI strategist and founder of PromptEngineering.org.
“Determining how much data is needed to train a language model is an empirical question best answered through systematic experimentation at different orders of magnitude. By measuring model performance across varying data scales and considering factors like model architecture, task complexity, and data quality, NLP practitioners can make informed decisions about resource allocation and continuously optimize their language models over time.”
Transfer learning, i.e., when a model is initially pre-trained on a data-rich task before being finetuned on a downstream task, can be considered viable for AI training. One of the conclusions researchers derived from Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer study is as follows:
“One beneficial use of transfer learning is the possibility of attaining good performance on low-resource tasks. Low-resource tasks often occur (by definition) in settings where one lacks the assets to label more data.”
3. Synthetic data
When obtaining real-world data becomes problematic (such as websites banning web crawlers), expensive, or downright impossible after the well runs dry, synthetic data will come to the rescue. Gartner predicted that by 2026, 75% of businesses will use generative AI to create synthetic customer data.
Synthetic data has the benefit of having similar mathematical patterns without the information of the original data from which it was derived. It is algorithmically generated via computer simulations filled with new scenarios that an LLM can gorge upon.
Synthetic data can prove highly beneficial in limiting organizations’ dependence on internet data for LLM training. It bears the same correlations and statistical properties as real-world data but can go beyond artificially creating and introducing situations that can enrich the training experience.
Colossal amounts of synthetic data can be created relatively quickly with the help of existing LLMs, enabling faster development and project turnaround times. To that end, methods like DeepMind’s Reinforced Self-Training (ReST) for Language Modeling can help.
However, synthetic data has limitations, including biased responses, inaccuracies, hallucinations, and security and privacy risks. It can also be quite simplistic and thus fail to capture the nuances of real-world scenarios.
Machine-generated synthetic data may also cause LLMs to become an echo chamber of poor outputs, leading to what researchers call Mad Autophagy Disorder (MAD). In Self-Consuming Generative Models Go MAD, researchers concluded, “Without enough fresh real data in each generation of an autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease.”



