Using window functions for advanced data analysis


Window functions are an advanced feature of SQL that provides powerful tools for detailed data analysis and manipulation without grouping data into single output rows, which is common in aggregate functions. These functions operate on a set of rows and return a value for each row based on the calculation against the set.
In this article, we delve into window functions in SQL Server. You will learn how to apply various window functions, including moving averages, ranking, and cumulative sums, to achieve comprehensive analytics on data sets.
You will also see how to partition and filter data using the window functions.
Finally, you will study some best practices and pitfalls to avoid when working with the Window functions. These are the types of things that are covered during the more advanced SQL workshops that are available online.
Note: We will use the Microsoft Pubs database as an example to execute various window function queries.
Understanding window functions
Window functions are used for calculations across sets of rows related to the current row. Unlike standard aggregate functions, window functions do not collapse rows and allow us to perform calculations across rows related to the current row. This capability is crucial for running totals, moving averages, and cumulative statistics, which are invaluable for time-series data analysis, financial data, inventory management, and more.
With window functions, you can specify a “window” of rows related to the current row over which SQL Server performs a calculation. You can define this window using clauses like OVER, PARTITION BY, and ORDER BY.
Basic syntax
The basic syntax for a window function is:
{function_name}() OVER ( |
Each part of the syntax has a specific purpose:
- {function_name}(): This is the window function you want to apply. SQL supports various window functions such as SUM(), AVG(), COUNT(), RANK(), ROW_NUMBER(), and more. These functions can compute values over a specified range of rows.
- OVER: This keyword defines the window over which the SQL server executes the function. It signifies the start of the window specification.
- PARTITION BY: Divides the data into partitions (or groups) to which the function is applied. If you don’t include the PARTITION BY clause, all the rows will be treated as a single partition.
- ORDER BY: Defines the order of data within each partition.
Practical scenarios using window functions
Let’s explore some practical scenarios using window functions on the Microsoft Pubs database. We will look into calculating moving averages, ranking, and cumulative sums.
Calculating moving averages for sales quantities
Moving averages smooth out data series and are commonly used to understand trends.
Let’s calculate a moving average for the sales quantities in the sales table of the Pubs database.
USE pubs
SELECT ord_num, ord_date, qty,
AVG(qty) OVER (ORDER BY qty ROWS UNBOUNDED PRECEDING) AS MovingAvgQty
FROM sales;
Output:
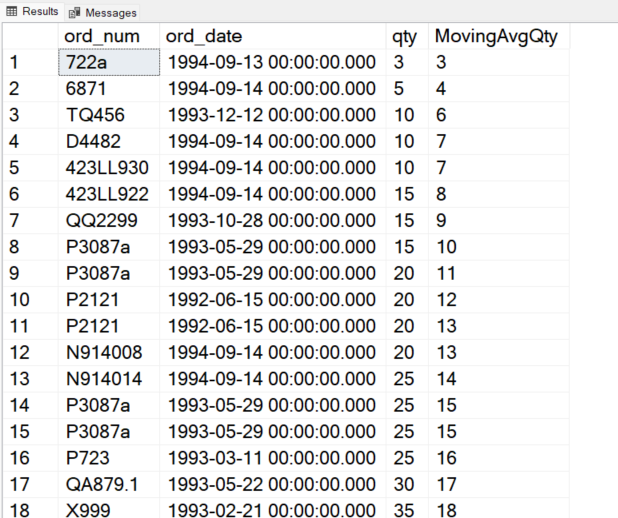
In the above query, we use the AVG window functions to calculate the moving average for the qty column. The ROWS UNBOUNDED PRECEDING means we want to calculate the moving average of all the previous rows up to the current ones.
You can also calculate the moving average for a specific number of previous rows.
For example, the following script returns the moving average for the previous two rows and the current row. Notice here that we cast the qty column to a floating type to have a precise average value.
USE pubs
SELECT ord_num, ord_date, qty,
AVG(CAST(qty AS float)) OVER (ORDER BY qty ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS MovingAvgQty
FROM sales;
Output:
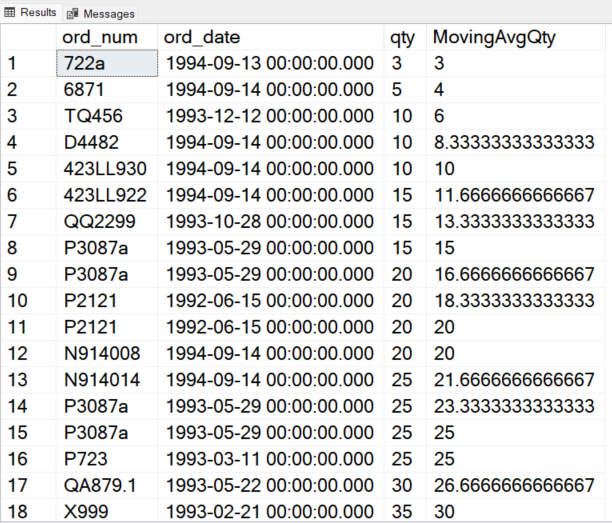
Ranking Sales Data by Price
Ranking can help in comparing items, like listing products by sales price.
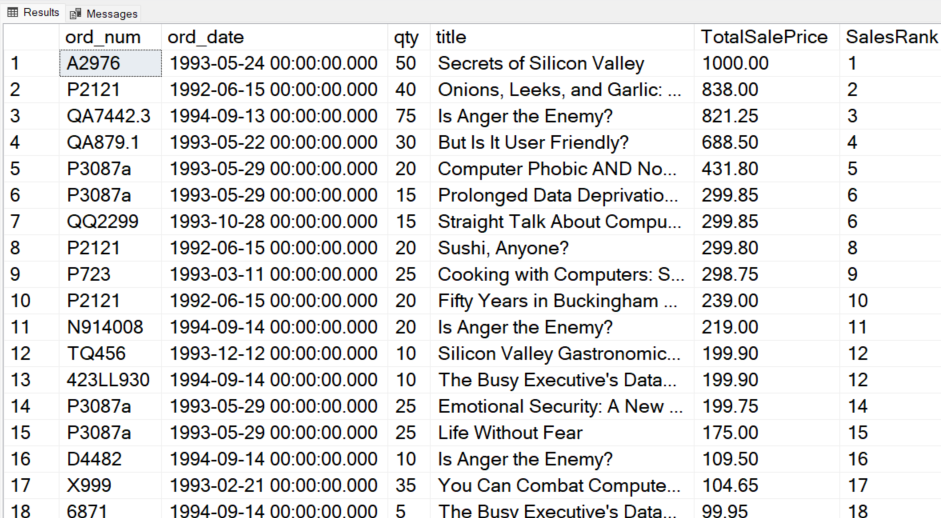
Let’s see an example where we rank the total sales price for each sale. We will first join the sales and titles tables. Next, we will calculate the total sale price for each record by multiplying qty with the price column of the corresponding tables). Finally, we will use the RANK function to rank all the records in descending order of the total sale price. This will give you information about which sale made the most money.
SELECT
S.ord_num,
S.ord_date,
S.qty,
T.title,
S.qty * T.price AS TotalSalePrice,
RANK() OVER (ORDER BY S.qty * T.price DESC) AS SalesRank
FROM
sales S
JOIN
titles T ON S.title_id = T.title_id;
Output:
Cumulative Sums of Total Sales Price
Cumulative sums are useful for running totals, which can be essential for inventory or account balance tracking.
For example, let’s calculate the cumulative total sale prices for all the rows in the sales table. As we did previously, we will join the sales and titles column to calculate the total sale price for each row.
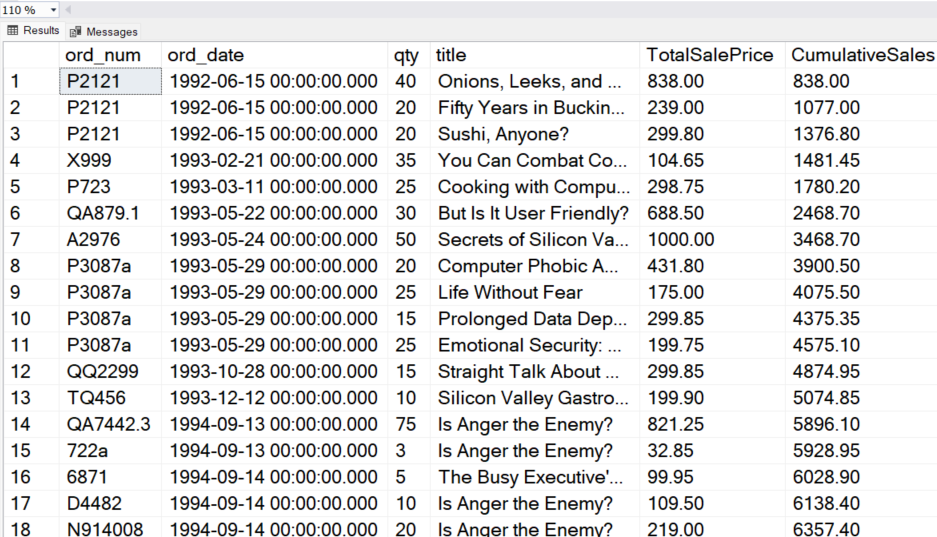
Next, you can use the SUM window function to calculate the cumulative sales by ordering the results using the ord_date column. This will return you the cumulative sales by date.
USE pubs;
SELECT
S.ord_num,
S.ord_date,
S.qty,
T.title,
S.qty * T.price AS TotalSalePrice,
SUM(S.qty * T.price) OVER (ORDER BY s.ord_date ROWS UNBOUNDED PRECEDING) AS CumulativeSales
FROM
sales S
JOIN
titles T ON S.title_id = T.title_id;
Output:
Partitioning and Filtering with Window Functions
You can partition and filter records in a window function using the PARTITION BY and the CASE statement.
Partitioning with PARTITION BY Clause
You can use the PARTITION BY clause in conjunction with window functions. This allows you to apply window functions separately for each partition.
For example, the following query returns cumulative prices for various title types in the titles table.
USE pubs;
SELECT
title_id,
title,
type,
price,
SUM(price) OVER (PARTITION BY type ORDER BY price ROWS UNBOUNDED PRECEDING) AS CumulativePriceByType
FROM
titles
Output:
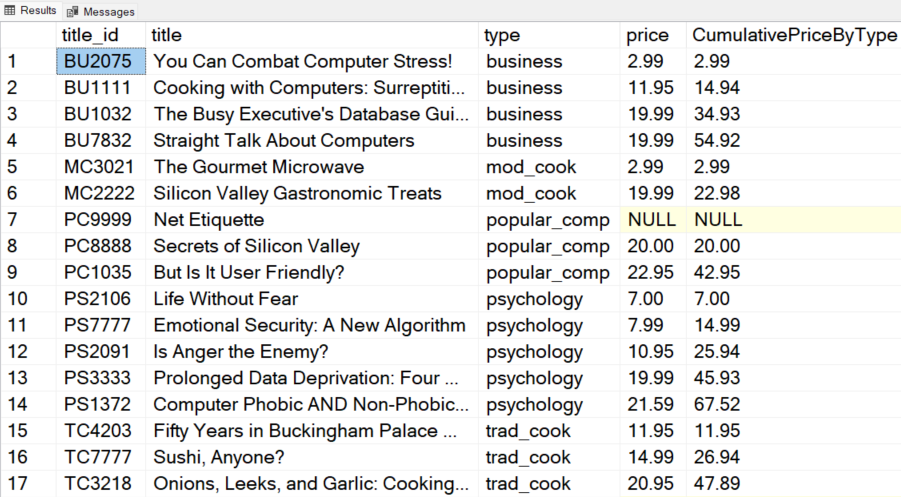
In the above output, cumulative prices are calculated separately for each title type.
Filtering with CASE Statement
You can use the CASE statement inside a window function to filter the records before applying the window function.
For example, you can use the following query containing the CASE statement if you only want to include titles in the cumulative sum where the price is greater than $10:
SELECT |
Output:
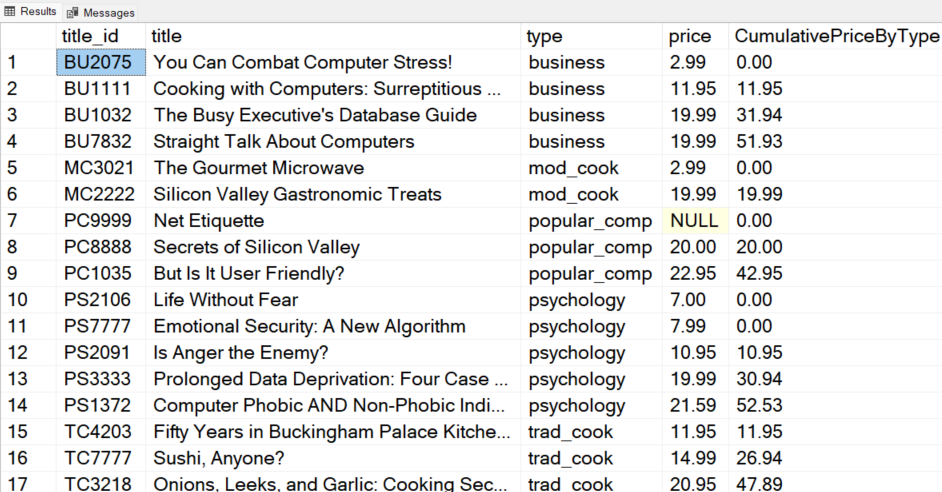
Best Practices and Common Pitfalls When Using Window Functions
Let’s now discuss some of the best practices and common pitfalls to avoid when using window functions in SQL Server.
Best practices
- Indexing for Performance: Ensure columns used in ORDER BY and PARTITION BY are indexed to improve query performance, especially with large datasets.
- Use PARTITION BY Judiciously: Use PARTITION BY thoughtfully. Overpartitioning, especially by columns with high cardinality, can reduce performance. Balance meaningful data segmentation with efficiency.
- Limit Window Frames: Use specific boundaries like ROWS or RANGE to limit window sizes instead of defaulting to UNBOUNDED PRECEDING, which improves performance by reducing the number of rows processed.
Common pitfalls
- Ignoring NULL Values: Window functions include NULL values by default. To ensure accuracy, exclude or handle NULLs as necessary.
- Forgetting to Order Data: Omitting ORDER BY can yield incorrect results since the order of rows affects calculations like running totals or moving averages.
- Performance Issues: Be mindful of potential performance issues with large datasets or complex queries. Check execution plans to identify and mitigate bottlenecks.
Conclusion
Window functions in SQL Server are indispensable tools for anyone seeking to perform sophisticated data analysis without the constraints of traditional aggregate functions. Their ability to operate over a set of rows and dynamically compute values makes them essential for various applications—from financial modelling and time-series analysis to inventory management.
In this article, you saw how SQL window functions work with the help of different practical scenarios. You also learned how to partition and filter data using window functions and what are the best practices and pitfalls to avoid when using window functions.



