A generative AI use case using Amazon RDS for SQL Server as a vector data store

Generative artificial intelligence (AI) has reached a turning point, capturing everyone’s imaginations. Integrating generative capabilities into customer-facing services and solutions has become critical. Current generative AI offerings are the culmination of a gradual evolution from machine learning and deep learning models. The leap from deep learning to generative AI is enabled by foundation models. Amazon Bedrock offers easy access to a wide range of foundational models and greatly simplifies the overall development experience.
However, despite their power, generic models can’t create specific and relevant AI solutions alone. Additional domain context is needed to generate better and more useful responses. Retrieval augmented generation (RAG) is a popular technique for providing context. Core to RAG are vector embeddings, which transform unstructured data into multi-dimensional numerical representations via foundation models. The closer the vector values within a dimension, the more similar the items. This is the basis for the vector similarity search use cases we see today.
Amazon Relational Database Service (RDS) for SQL Server is a fully managed, durable database service used by organizations of all sizes worldwide. For many customers, the operational data store that can provide additional domain context for RAG-based generative AI use cases is already hosted on Amazon RDS for SQL Server. As a result, this database service is an excellent choice as a vector data store for the following reasons:
- Amazon RDS for SQL Server is a highly mature, scalable, reliable, and efficient relational database service that facilitates overall vector data management.
- Vectors can be modeled as relational tables within a SQL Server database.
- SQL Server columnstore indexes offer built-in optimizations including SIMD and AVX-512 that accelerate vector operations.
- Cosine similarity, a popular similarity calculation for vectors today, can be implemented as a user-defined function in a SQL Server database.
In this post, we demonstrate how to use Amazon RDS for SQL Server as a vector data store to implement a generative AI use case involving similarity search. In this scenario, both the source operational data store and vector data store are co-located and hosted on Amazon RDS for SQL Server. Storing embeddings close to your domain-specific datasets allows combining them with additional metadata without needing external data sources. Since your data changes over time, storing the embeddings near the source data also simplifies keeping the embeddings up to date.
For this post, we used the same RDS for SQL Server instance for both operational data and the vector data store. The specific workflow we demonstrate is based on a typical chatbot scenario using RAG to augment a foundation model and provide a domain-relevant response to the user. The following diagram is a high-level depiction of the generative AI workflow implemented for this post.
We assume vector embeddings for the source data already exist in the vector data store. Our primary focus will be generating vector embeddings for the chat question, comparing them to the vector data store, and producing a relevant response using similarity search. The data for this post originates from Wikipedia’s publicly available content, comprising four fields: id, URL, title, and text. The process of generating vector data embeddings in a vector database within Amazon RDS for SQL Server using the sample Wikipedia data will be covered comprehensively in our next post (part 2).
The UI implementation details leveraging the large language model to provide a conversational response to the user have been intentionally excluded from this scenario. The focus is kept on the database aspects of the solution: how to retrieve a relevant result set from the vector data store in response to a similarity search request.
Solution architecture overview
The solution architecture deployed to implement the RAG workflow described above involves Amazon RDS for SQL Server, Amazon SageMaker, and Amazon Bedrock, specifically the Amazon Titan G1 Text Embedding Model. The workflow is as follows:
- The user question (prompt) is transformed into a vector embedding using the Amazon Titan model, by invoking the Amazon Bedrock API from a SageMaker notebook (steps 1 through 3 in the diagram that follows).
- This new vector is then passed as input to the cosine similarity function hosted in our vector data store. The function runs a similarity search against vector embeddings already persisted in the database and returns the result set to SageMaker (steps 4 and 5 in the following diagram).
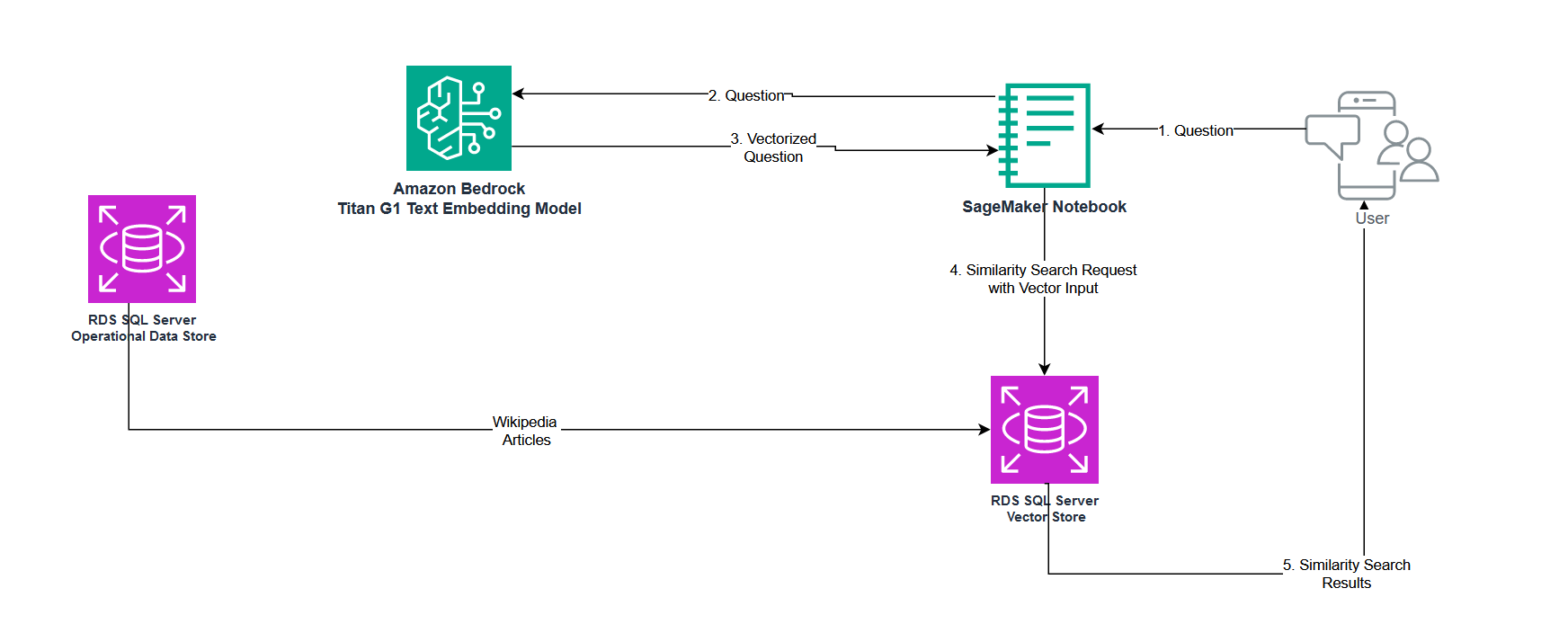
In the following sections, we walk through setting up this solution architecture using Amazon RDS for SQL Server, Bedrock, and SageMaker. We also provide detailed explanations on how to interact with Amazon Bedrock Foundation Models and run cosine distance calculations from our vector data store.
Prerequisites
This post assumes familiarity with navigating the AWS Management Console. For this example, you also need the following resources and services enabled in your AWS account:
Create an Amazon RDS for SQL Server vector data store
The basic building block of Amazon RDS for SQL Server is the database instance. This environment is where you run your SQL Server databases. For this demo, refer to the instructions included in the chapter Creating and connecting to a Microsoft SQL Server DB instance from our user guide.
Make sure the following options are selected:
- For Engine Options, select Microsoft SQL Server
- For Engine Version, select SQL Server 2019 15.00.4345.5.v1
- For Edition, select SQL Server Standard Edition
- For DB Instance Class, select db.t3.xlarge
- For Storage Type, select GP3
- For Public Access, select Yes. This will allow you to directly connect to your RDS for SQL Server instance from your workstation.
- For Option Group, select an option group that includes the SQLSERVER_BACKUP_RESTORE option. This is required to be able to restore the SQL Server native backup provided in this article. For detailed instructions refer to the chapter Importing and exporting SQL Server databases using native backup and restore in our user guide.
Once you have completed creating an Amazon RDS for SQL Server instance and restoring the provided vector database backup you should be able to browse to a database called [vector_db_wiki], as follows.

The [vector_db_wiki] database should contain three tables:
wikipedia_articles(raw source data for our use case)wikipedia_articles_embedding_bedrockwikipedia_articles_content_vector
And one user-defined function that implements the cosine similarity logic:
Bedrock_SearchSimilarContentArticles
Configure SageMaker Notebook
Before we can upload the sample Amazon SageMaker notebook provided in this post, we need to setup an Amazon SageMaker Notebook instance. In your AWS Subscription, navigate to the SageMaker service, expand the Notebook section in the left pane, select the Notebook instance option, and choose the “Create notebook instance” button as follows.

Type-in “rds-sql-genai-demo” as the name for your notebook instance and keep all the remaining default values as follows.

Expand the “Network” section, select an appropriate “VPC”, “Subnet”, and “Security group”. Make sure that the Amazon RDS for SQL Server database instance created earlier to follow along with this demo is deployed on the same virtual private cloud (VPC) selected above to avoid any database connectivity issues. Scroll down and click on the “Create notebook instance” button. Once the Notebook Instance has launched (“InService” status), choose the “Open JupyterLab” link. You will be re-directed to the JupyterLab IDE as follows. Choose the “Terminal” icon.
Run the following code in the Linux terminal window to install the Microsoft Open Database Connectivity (ODBC) driver for SQL Server (Linux).
# RHEL 7 and Oracle Linux 7
curl https://packages.microsoft.com/config/rhel/7/prod.repo | sudo tee /etc/yum.repos.d/mssql-release.repo
sudo yum remove unixODBC-utf16 unixODBC-utf16-devel #to avoid conflicts
sudo ACCEPT_EULA=Y yum install -y msodbcsql18
# Optional: for bcp and sqlcmd
sudo ACCEPT_EULA=Y yum install -y mssql-tools18
echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc
source ~/.bashrc
# For unixODBC development headers
sudo yum install -y unixODBC-develInstall additional required libraries by executing the following code.
pip install --no-build-isolation --force-reinstall \
"boto3>=1.28.57" \
"awscli>=1.29.57" \
"botocore>=1.31.57"It is safe to ignore the pip dependency error that’s displayed towards the end of the installation process as follows.
Install the “utils” library by executing the following code. Once installation completes, copy the file bedrock.py to the /home/ec2-user/anaconda3/envs/python3/lib/python3.10/site-packages/ directory in the local drive of your SageMaker Notebook instance.
pip install utilsNow, let’s upload the provided sample SageMaker Notebook. If you haven’t downloaded the notebook file yet, please do so before continuing. Your Downloads folder should contain a file called vector-similarity-search-bedrock-sql-server.ipynb.
Choose the “Open JupyterLab” link at the right of your SageMaker notebook instance. Now choose the folder icon located in the left pane of your Jupyter Lab window. Select the “Upload Files” option, browse to the Downloads folder, and select the “vector-similarity-search-bedrock-sql-server.ipynb” file as follows.

As soon as the file is uploaded you should be able to browse our sample SageMaker notebook as shown.

Run a Similarity Search
In this section we run a couple of similarity search use cases using SageMaker Notebook. Before we can run any of the Bedrock APIs included in this document, we need to setup an IAM role that we use as our security context for all our API calls. Follow the instructions included in the documentation to setup the required IAM role.
The first step is to import a set of required libraries the code will be referencing. Select the following code snippet and execute it using the play button in the JupyterLab toolbar, or highlight the cell and press Shift+Enter.

Next, configure the Amazon Bedrock Client executing the code snippet below. Make sure that you replace the Account Number and Role Name with appropriate values before executing the code. Upon completion, you should see in the SageMaker Notebook the message “boto3 Bedrock client successfully created!”.

Now let’s make our first Bedrock API call to vectorize the user prompt for our first similarity search (“What are the best Sci-Fi movies in history?”) by executing the following code snippet. It is important to note that the text embedding model we are using is Amazon Titan Embeddings G1 – Text v1.2 (line 1 of the code snippet).

Once an input vector has been created, we are ready to establish connectivity with our Amazon RDS for SQL Server based vector data store and issue a similarity (semantic) search request leveraging the cosine distance algorithm, executing the code below. Make sure that all the right parameters have been provided for the ODBC connection string beforehand.
![]()

After a few seconds, you should obtain a result set like the following. The values shown next to each Wikipedia article represent the result of the cosine distance calculation between the prompt vector and the vectors generated for each source Wikipedia article currently stored in the wikipedia_articles_content_vector table (our content vector table).
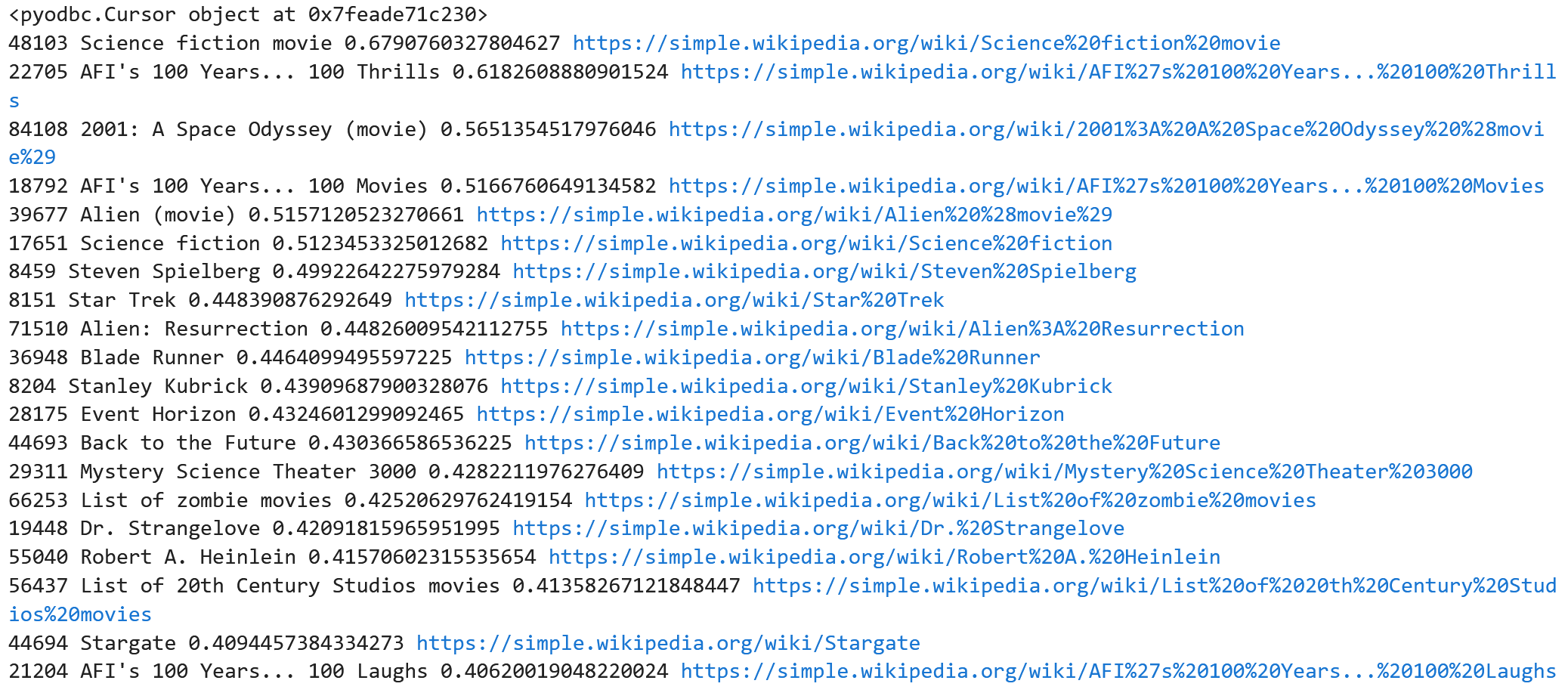
Note that Wikipedia Articles like “Alien”, “2001: A Space Odyssey”, and “Blade Runner” show high in the list even though there is no mention of the word “Sci-Fi” or “Movie”; this is certainly not achievable with traditional text search. Also note a reference to the article “AFI’s 100 Years… 100 Movies” showing almost at the top of the list, which makes perfect sense considering that this article talks about the top 100 films according to the American Film Institute. Now, as a final example, let’s issue another similarity (semantic) search request with the prompt “What are the most iconic warriors in history?” as shown.

![]()
After a few seconds, you should obtain the following result set.

Notice how the result set includes Wikipedia articles like “Zhang Fei”, “Leonidas I”, and “Sitting Bull”. All these iconic warriors from different times and places in history: ancient China, Sparta, and the iconic Sioux chief that fiercely fought against the American settlers. Another relevant detail to call out is how items are ordered within the result set, by cosine distance in descending order, very high in the list, with a cosine distance value of 0.457988230404067: “Leonidas I” a Wikipedia article about the legendary Spartan warrior.
If you intend to keep these resources for additional testing and development, a simple way to minimize ongoing costs is to stop the RDS for SQL Server and SageMaker Notebook instances. Otherwise, delete these resources as described in the clean-up section.
Clean-up
Running this demo created a few AWS resources:
- Amazon RDS for SQL Server database instance
- Amazon SageMaker Notebook instance.
If you don’t need these resources going forward, make sure to delete the Amazon RDS for SQL Server and SageMaker Notebook instances to avoid unnecessary charges following the instructions available in the provided URLs.
Conclusion
Retrieval augmented generation (RAG) is a powerful technique that enhances responses in generative AI applications by combining domain-specific information with a foundation model. In this post, we covered two similarity search use cases using Amazon RDS for SQL Server, Amazon SageMaker, and Amazon Bedrock. We also demonstrated how Amazon RDS for SQL Server can function as a vector data store. We highly recommend that customers conduct thorough performance and scale testing before deploying any solutions to production. This will ensure similarity search response latencies meet the required expectations. To learn more about the role of vector data stores in generative AI applications, see our overview on the role of vector datastores in generative AI applications.
About Authors
 Joshua Jin is a database benchmark engineer at Amazon Web Services (AWS), where he specializes in meticulously evaluating the performance of databases.
Joshua Jin is a database benchmark engineer at Amazon Web Services (AWS), where he specializes in meticulously evaluating the performance of databases.
 Camilo Leon is a Principal Solutions Architect at AWS specialized on databases and based off San Francisco, California. He works with AWS customers to provide architectural guidance and technical support for the design, deployment and management of their AWS relational database workloads and business applications. In his spare time, he enjoys mountain biking, photography, and movies.
Camilo Leon is a Principal Solutions Architect at AWS specialized on databases and based off San Francisco, California. He works with AWS customers to provide architectural guidance and technical support for the design, deployment and management of their AWS relational database workloads and business applications. In his spare time, he enjoys mountain biking, photography, and movies.
 Sudarshan Roy is a Senior Database Specialist Cloud Solution Architect with World Wide AWS Database Services Organization (WWSO). He has led large scale Database Migration & Modernization engagements for Enterprise Customers and his passionate of solving complex migration challenges while moving database workload to AWS Cloud.
Sudarshan Roy is a Senior Database Specialist Cloud Solution Architect with World Wide AWS Database Services Organization (WWSO). He has led large scale Database Migration & Modernization engagements for Enterprise Customers and his passionate of solving complex migration challenges while moving database workload to AWS Cloud.
 Barry Ooi is a Senior Database Specialist Solution Architect at AWS. His expertise is in designing, building and implementing data platform using cloud native services for customers as part of their journey on AWS. His areas of interest include data analytics and visualization.
Barry Ooi is a Senior Database Specialist Solution Architect at AWS. His expertise is in designing, building and implementing data platform using cloud native services for customers as part of their journey on AWS. His areas of interest include data analytics and visualization.



