AIQ: Has Generative AI Peaked? (NASDAQ:AIQ)
")
Jonathan Kitchen
Introduction
Since the public introduction to ChatGPT in 2022, generative AI has been in the public consciousness nonstop. These AI bots are now all over the place. Google introduced Gemini and Bard, Microsoft introduced Bing, and OpenAI’s ChatGPT is now merged with DALL-E so that its 4th version can now produce images in seconds. These kinds of AI are large language models (“LLMs”) and operate in a way that has captured significant attention from the public and investors.
This hype has translated into stock market gains, and funds like the Global X Artificial Intelligence & Technology ETF (NASDAQ:AIQ), which has outperformed the S&P 500 since inception.
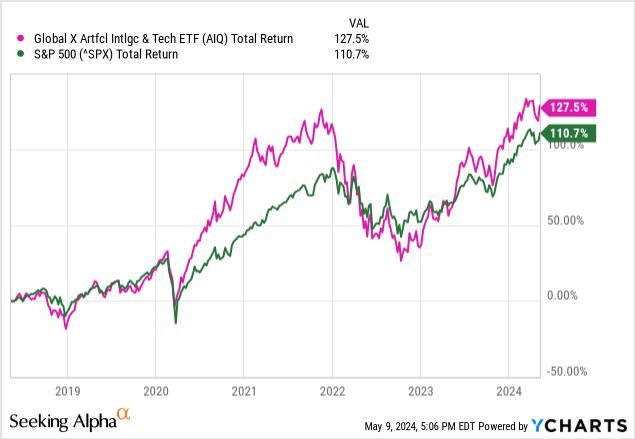
Global X claims that these gains can remain exponential:
Spurred by breakthroughs in generative AI, forecasts suggest the global artificial intelligence market could increase more than 300x from $39bn in 2022 to $1.3tn by 2032.
…
AI is quickly expanding beyond data centers, enabling innovative commercial applications in diverse sectors, including Agriculture, Health Care, and beyond. Forecasts indicate that over 729mm individuals will use AI tools by 2030, up 254mm from 2023.
In this article, I am going to challenge the narrative that AI can continue to justify these gains. AIQ and subsequent AI focused ETFs are built on a popular narrative and hype. It has reached a rich valuation that far exceeds AI’s capacity to improve.
Fund Overview
The Global X Artificial Intelligence & Technology ETF is a thematic ETF tracking companies working in the AI space. This includes big names such as NVIDIA Corp. (NVDA), Tencent Holdings (OTCPK:TCEHY), and Netflix, Inc. (NFLX).
Here is a list of the top ten holdings:
Figure 1 (Global X)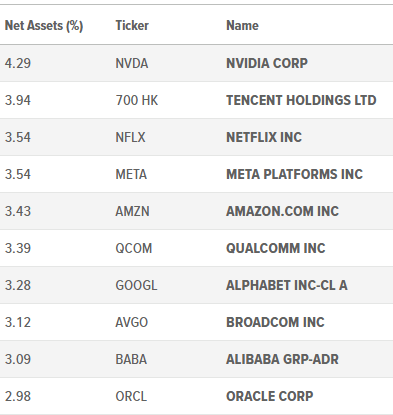
Its smallest holdings give the fund more of a “pure play,” as it includes companies more solely focused on AI such as C3.ai (AI), CCC Intelligent (CCCS), and CyberArk Software (CYBR).
The fund has an expense ratio of 0.68%, higher than the competitive average of 0.50%. This is one of the big losing points for Global X funds in general, and AIQ more specifically.
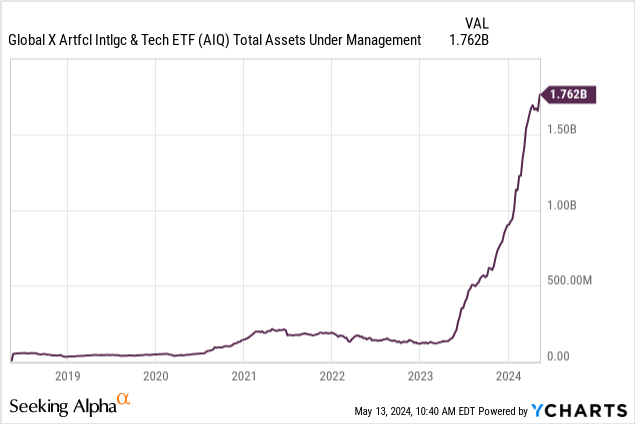
This higher-than-average ER hasn’t stopped the AUM from piling up. AIQ had flown under the radar until mid-2023, as shown below. Today, AIQ sits at $1.76B AUM.
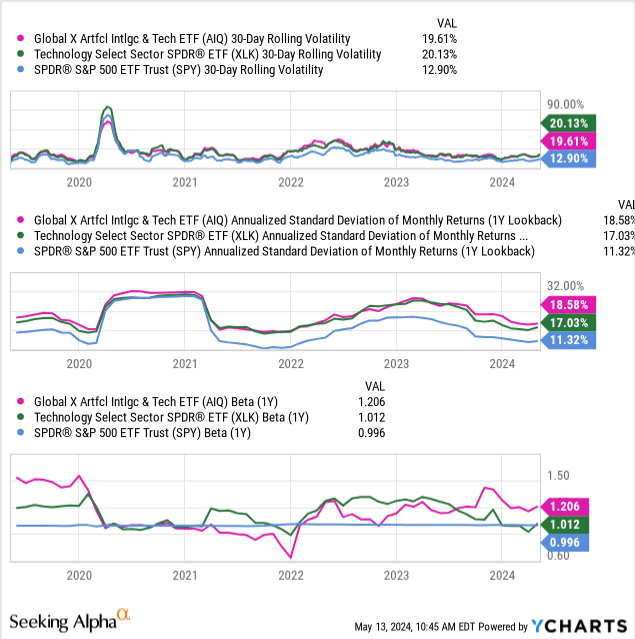
The fund itself is very volatile, as is the tech sector as a whole, but AIQ stands out in its volatility because it is taking on an emerging technology. AI endeavors cost a lot of money, often tens or hundreds of millions of dollars, before they can show any results. This means that smaller firms are betting the farm on their product, and failure may mean massive sell-offs in their stock.
We can see this volatility in three metrics: rolling vol, standard deviation, and beta. AIQ beats out the S&P broadly and the S&P tech sector in both standard deviation and beta, but aligns with the general sector in rolling volatility.
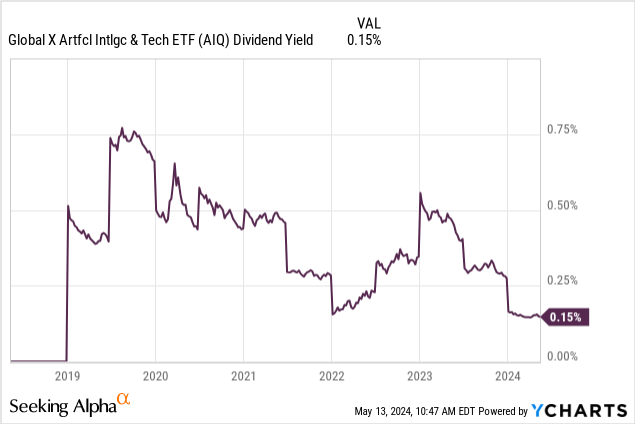
The fund does not pay a substantial dividend, which is to be expected from companies in this sector which need as much cash on hand as possible to fund expensive AI training endeavors.
How LLMs Work
To start this section, we need to quickly cover how large language models are trained. These models are fed mountains of data, in GPT 4’s case, 570GB of text data (which is absolutely enormous for those who are unfamiliar with data storage). That process cost OpenAI at least $100M.
Machine learning algorithms create a neural network, which looks like a much larger version of this:
Figure 2 (Calin Cretu)
Each of these data points is a piece of vocabulary that ChatGPT (or insert any competing LLM) understands. These are all assigned numbers, which can be crunched by the algorithms. When asked to complete sentences, which is the primary function of an LLM, the bot has to “guess” which word is most likely to follow the previous ones.
Figure 3 (Calin Cretu)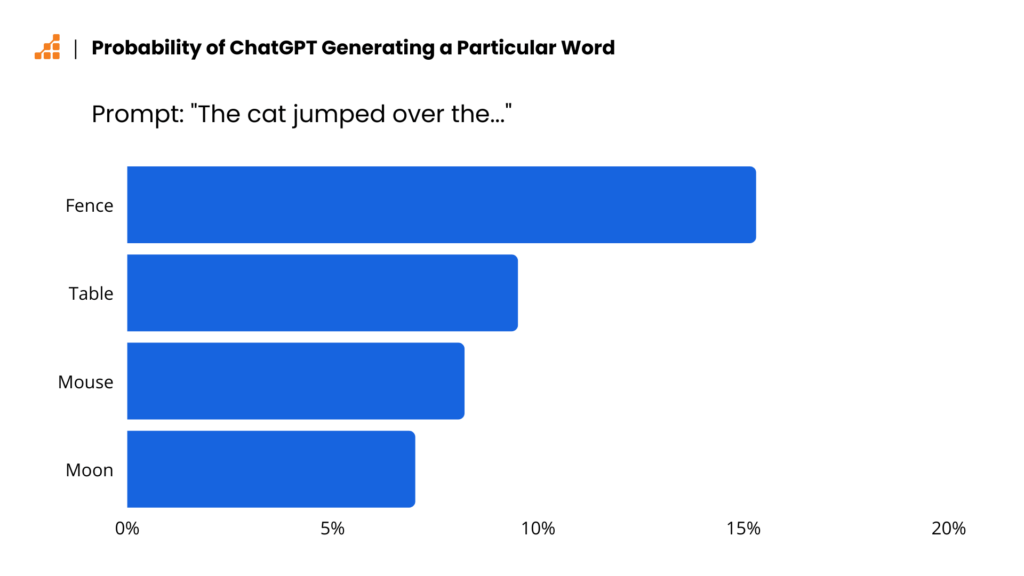
This is a very oversimplified explanation and skips a lot of the technical behind-the-scenes of how LLMs are built. I am not going to get too deep into those weeds because it isn’t relevant to my thesis, but if you want a deeper dive, I suggest reading this breakdown by machine learning engineer Calin Cretu.
Bigger Isn’t Better
The first issue we have, and the first reason why I believe generative AI has plateaued in its current form, is that bigger isn’t always better when it comes to datasets.
Sam Altman, CEO of OpenAI, spoke at MIT last year about AI and said:
I think we’re at the end of the era where it’s going to be these, like, giant, giant models…We’ll make them better in other ways.
Adding in more and more training data was the way ChatGPT moved from 3.5 to 4, which has outperformed on most tasks, but not all.
Figure 3 (Brian Chau)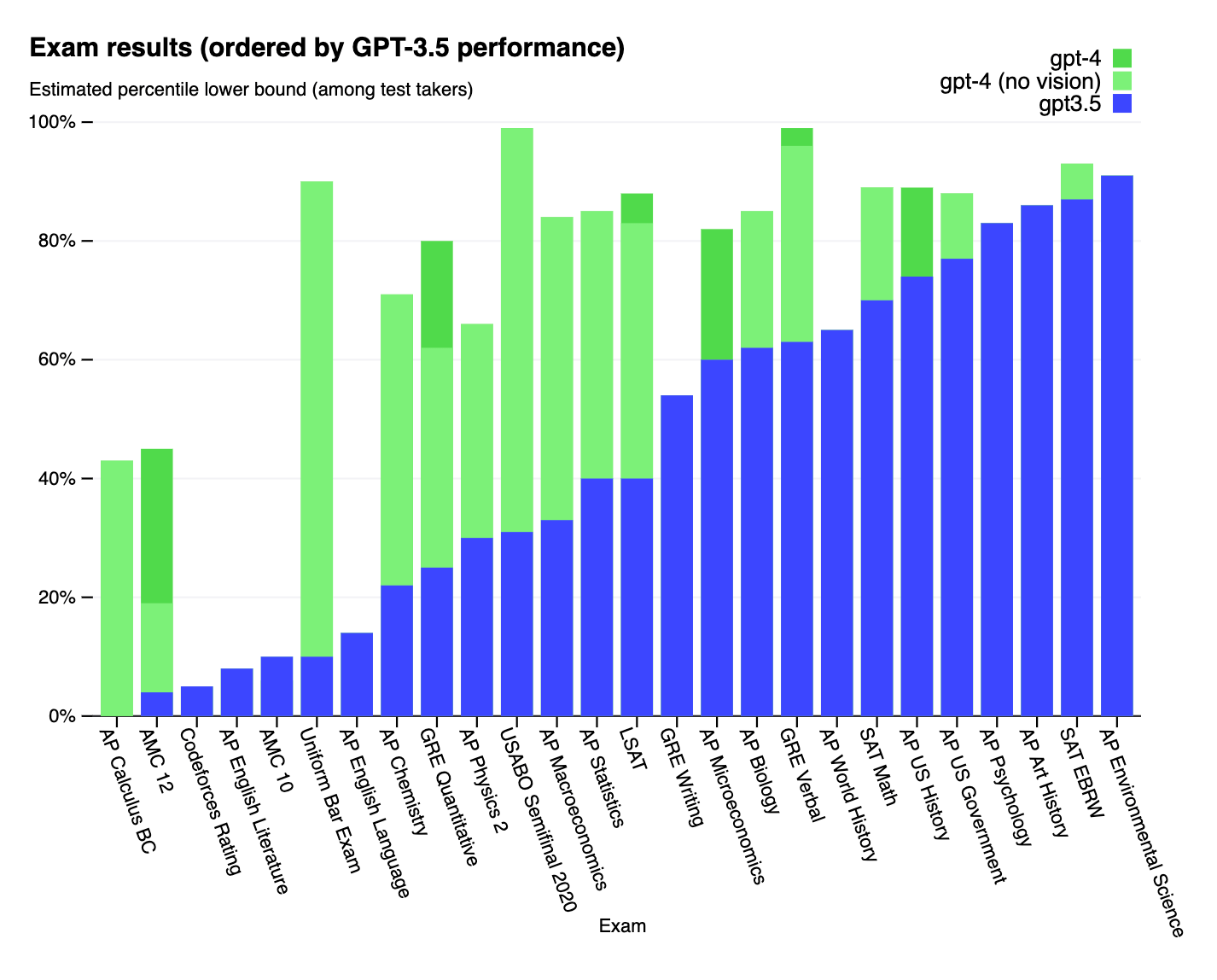
So we are already starting to see diminishing returns, especially in some of the areas where both GPT 3.5 and 4 underperformed the average human, like in the AP English Literature and Language exams. These are exams given to high schoolers.
The general understanding is that AI is limited to how much data we can throw at them and how much computing power they have, but this is incorrect. Adding more and more data doesn’t always produce better results.
One of the core causes of Gemini’s overcorrection issues, where the model had an incredibly difficult time producing correct images for prompts (that is really oversimplified, see the article for more details), was that its training data was too large. The larger the data set, the more hallucinations it would produce.
However, feeding more data to these models is the most cost-effective way to produce better results, as shown in Figure 3, where GPT 4 was able to drastically improve some of the results like in the Uniform Bar Exam.
This problem is understood by OpenAI internally, who have already nixed hopes for GPT-5 happening any time soon.
Diminishing Returns
These models offer less and less for the more money they have thrown at them, typically. In a paper recently published by computer scientists at the University of Tübingen, Cambridge, and Oxford, thirty-four LLMs were inspected to see how larger and larger datasets affect the trajectory of performance.
Here are two of the tests, along with the team’s commentary (in quote blocks) from the study.
Figure 4 (Udandarao et al.)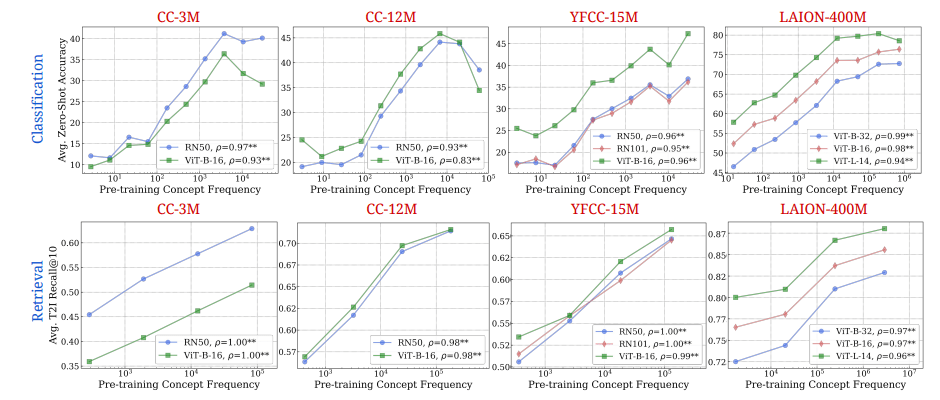
[The data above shows] log-linear relationships between concept frequency and CLIP zero-shot performance. Across all tested architectures…and pretraining datasets…we observe a consistent linear relationship between CLIP’s zero-shot performance on a concept and the log-scaled concept pretraining frequency. This trend holds for both zero-shot classification…and image-text retrieval.
Figure 5 (Udandarao et al.)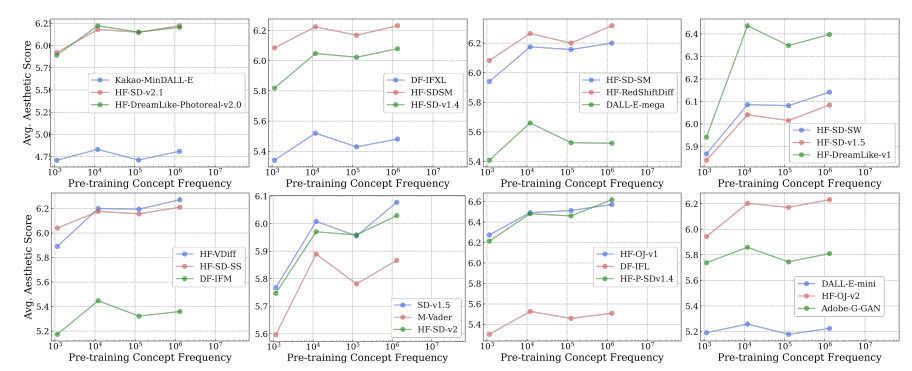
[The data above shows] log-linear relationships between concept frequency and T2I aesthetic scores. Across all tested T2I models pretrained on the LAION-Aesthetics dataset, we observe a consistent linear relationship between zero-shot performance on a concept and the log-scaled concept pretraining frequency.
Between Figures 4 and 5, we learn something very interesting: there is a log-linear relationship between pretraining data and AI outcomes. Even when the datasets are controlled to give the AI the best chance at breaking out of the log-linear performance path, they still show the same patterns.
Figure 6 (Udandarao et al.)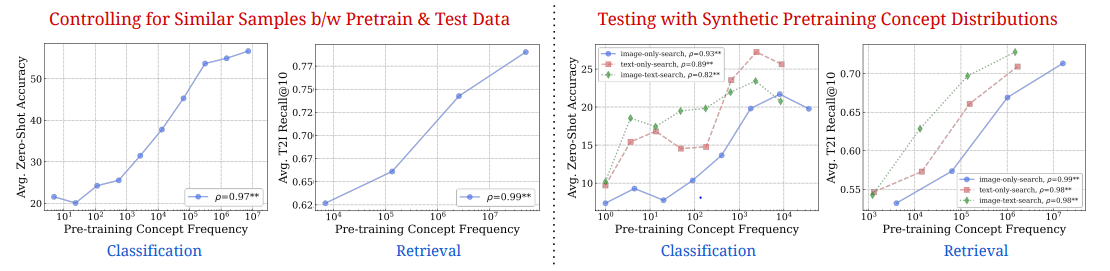
Log-Linear, Not Exponential
This log-linear progression in AI models means that exponential amounts of data are needed to produce logarithmic results. There is an incredible amount of diminishing returns going on with feeding AI models more data.
The easy solution many AI firms and startups were banking on, more money means more processing power, which means better AI, is coming out to be untrue. We are going to see AI models hit a plateau very soon if we haven’t already.
The difference looks like this, for reference.
Figure 7 (N. Haus)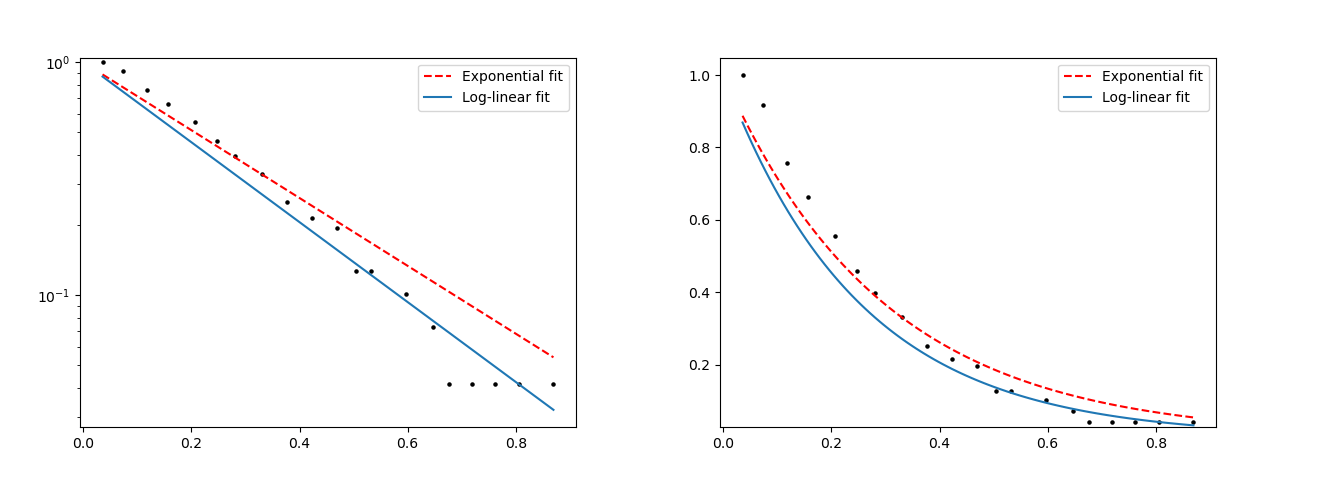
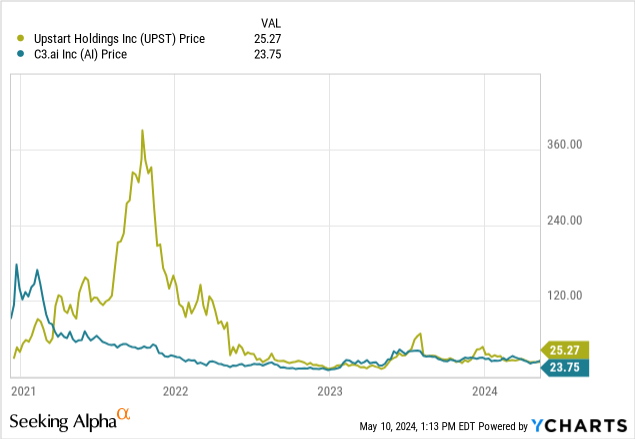
When expectations are not met, stocks fall. As AI continues to plateau in its progress, we will see these companies be left behind by the market. We can see this in other AI names that attracted a lot of attention early on and then disappointed when their performance ended up being linear and not exponential as expected, such as C3.ai and Upstart Holdings, Inc. (UPST).
Sigmoid Curves & Technology
Everett Rogers, in his book Diffusion of Innovations, argued that innovative technologies follow a sigmoid curve, i.e., a curve that makes an “S” shape. This is due to how technologies expand quickly, evolve faster than most people can keep up with, and then hit a wall and plateau.
Figure 8 (Everett Rogers)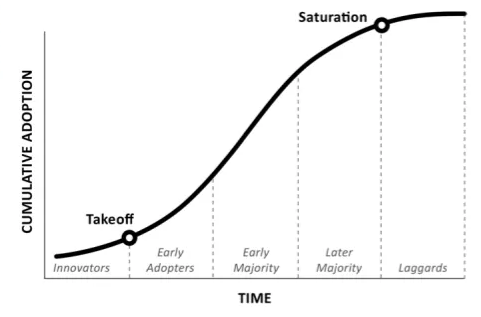
I believe that AI is now at the saturation point with its public rollout. ChatGPT, Gemini, and others may feel unpolished and are still prone to hallucinations, but that isn’t because they are about to be phased out of these bots. They are now staples in using these LLMs because phasing them out is too difficult for our current tech paradigm.
Until that paradigm changes and a new technology is introduced that can change how these LLMs work, we shouldn’t expect any new breakouts. This means that the companies in AIQ that are spending time and money working on these models are unlikely to be rewarded for this work, resulting in future underperformance.
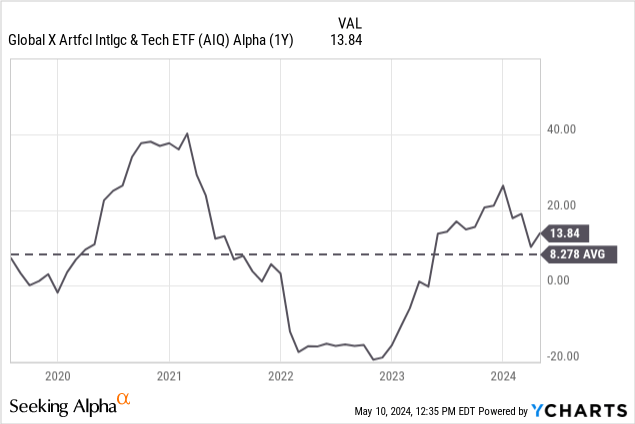
Due to this, I expect to see a future decline in AIQ’s alpha. The decline we saw in 2022 was temporary, as it was reacting to the market decline due to the Russo-Ukraine War and the Stagflation Crisis. Long-term alpha remains at an 8 average, but I believe this will — in the long run — average out far lower or even negatively due to AI becoming expensive projects which will show little progress for the amount invested.
Counterpoints
There are several points to be considered that may make AI more valuable in the short term even if I am correct in my assertion that we will not see any more major breakthroughs with LLMs in their current forms.
- LLMs are replacing customer service roles, which cut corporate costs. These models do not have to be perfect to replace large swaths of staff, and current LLMs are on their way to being “good enough” for general customer service positions like chatbots. This could raise profitability for many companies, which have humans as one of their largest expenses.
- The removal of hallucinations from the models would greatly enable them to be deployed alongside doctors, something that is currently being tested over at HCA Healthcare (HCA). Currently, AI are only used for administrative tasks in hospitals, but a larger rollout could eliminate much of the time taken by these professionals doing paperwork. This is also a large money-saver for corporations like HCA.
- The ability for AI to take over jobs that we do not want people to do, e.g., legal discovery where one has to read thousands of emails, would allow for human capital to be so much more efficiently deployed at many firms. Current LLMs are capable of this, albeit with some oversight to avoid hallucinations. AI, with its flaws, does not get tired reading thousands of emails. It won’t miss a line of text by reading too fast, or any of the other issues its human counterparts may encounter in these repetitive tasks.
Conclusion
Artificial intelligence ETFs like the Global X Artificial Intelligence & Technology ETF are capitalizing on investor hype over AI models and their capability to change our world. However, these models have deep flaws in their ability to operate effectively, are very expensive to train, and their training has seemed to hit a wall that will be impossible for them to overcome quickly.
For these reasons, I believe that the AI sector is overvalued, and I am giving it a ‘sell’ rating. Should another massive breakout in AI performance occur, such as a break-out into exponential progress based on additional training data or a total elimination of hallucinations, I will revise my stance.
Thanks for reading.



