Build a FedRAMP compliant generative AI-powered chatbot using Amazon Aurora Machine Learning and Amazon Bedrock

In this post, we explore how to use Amazon Aurora PostgreSQL-Compatible Edition and Amazon Bedrock to build Federal Risk and Authorization Management Program (FedRAMP) compliant generative artificial intelligence (AI) applications using Retrieval Augmented Generation (RAG). FedRAMP is a US government-wide program that delivers a standard approach to security assessment, authorization, and monitoring for cloud products and services. Cloud service providers must demonstrate FedRAMP compliance in order to offer services to the U.S. Government. RAG is often used in generative AI to enhance user queries and responses by augmenting the training of a large language model (LLM) with data from a company’s internal business systems.
The solution we demonstrate uses Amazon Aurora Machine Learning which enables builders to create machine learning (ML) or generative AI applications using familiar SQL programming. Aurora ML provides access to foundation models (FMs) in Amazon Bedrock for creating embeddings (vector representations of text, images, and audio) and generating natural language text responses for generative AI applications directly with SQL. With Aurora ML, you can create text embeddings, perform similarity search using the pgvector extension, and generate text responses within the same Aurora SQL function. This reduces latency for text generation because document embeddings may be stored in the same table as the text, minimizing the need to return a search response to applications.
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to help you build generative AI applications. Amazon Aurora PostgreSQL is a fully managed, PostgreSQL–compatible, and ACID–compliant relational database engine that combines the speed, reliability, and manageability of Amazon Aurora with the simplicity and cost-effectiveness of open-source databases.
Overview of solution
In this post, we demonstrate how to build an AI-powered chatbot with Aurora ML and Amazon Bedrock, both of which are FedRAMP compliant. The solution includes the following AWS services:
- Amazon Simple Storage Service (Amazon S3) as the data source
- Amazon Aurora PostgreSQL with the pgvector extension as the vector database
- Amazon Bedrock to generate embeddings for the documents and user queries and making calls to the LLM
We also use Streamlit to construct the interactive chatbot application running on AWS Cloud9.
The following diagram is a common solution architecture pattern you can use to integrate your Aurora PostgreSQL database with Amazon Bedrock using Aurora ML.
This architecture implements a RAG workflow. The first part involves ingesting the knowledge dataset, which contains unstructured data like PDFs and documents. This data is broken down into smaller chunks and embedded into vector representations using an embedding model such as Amazon Titan. The embeddings are stored alongside the original text chunks in Aurora, which serves as our vector database (Steps A and B).
The second part involves generating a response. First, the user’s question is converted into an embedding vector using the same embedding model . This question embedding is then used to perform semantic search over the database embeddings to determine relevant text chunks called the context. The context along with a prompt are formatted into a model input, which is fed to the text generation model to produce a natural language response to the question (Steps 1–4).
This implementation uses Amazon Aurora PostgreSQL with aws_ml (version 2) and the pgvector extension to store embeddings, Amazon Bedrock FMs (amazon.titan-embed-g1-text-02 for embeddings and anthropic.claude-instant-v1 for text generation), and Streamlit for the chatbot frontend. This can be deployed in three main steps:
- Ingest documents from Amazon S3 into an Aurora PostgreSQL table.
- Create embeddings with SQL functions.
- Run a chatbot query to generate responses.
Prerequisites
For this walkthrough, complete the following prerequisites:
- Have a valid AWS account. You must configure a VPC and AWS Cloud9 to run the chatbot application.
- Have an AWS Identity and Access Management (IAM) role in the account that has sufficient permissions to create the necessary resources. If you have administrator access to the account, no action is necessary.
- Install Python with the required dependencies (in this post, we use Python v3.9).
- Request access to the FM you want to use in Amazon Bedrock. Verify that you are in an AWS Region where Amazon Bedrock is available.
- Set up the Aurora PostgreSQL DB cluster. Please follow the Configure an Aurora PostgreSQL cluster instructions below and note the primary username and password for use in future steps.
- Configure your security group according to your organizational policy so it allows for your AWS Cloud9 to access the database.
- Follow the steps in Using Amazon Aurora machine learning with Aurora PostgreSQL to set up an IAM role and policy to give Amazon Aurora PostgreSQL permission to invoke Amazon Bedrock.
Configure an Aurora PostgesSQL cluster
- On the Aurora console, create a new cluster.
- For Engine options¸ select Aurora (PostgreSQL Compatible).
- For Engine version, choose your engine version.
We selected PostgreSQL 15.5 for this example; we recommend using PostgreSQL 15.5 or higher so you can use the latest version of the open source pgvector extension

- For Configuration options, select either Aurora Standard or Aurora I/O Optimized.
We selected Aurora I/O-Optimized, which provides improved performance with predictable pricing for I/O-intensive applications.
- For DB instance class, select your instance class.
We opted to use Amazon Aurora Serverless v2, which automatically scales your compute based on your application workload, so you only pay based on the capacity used.
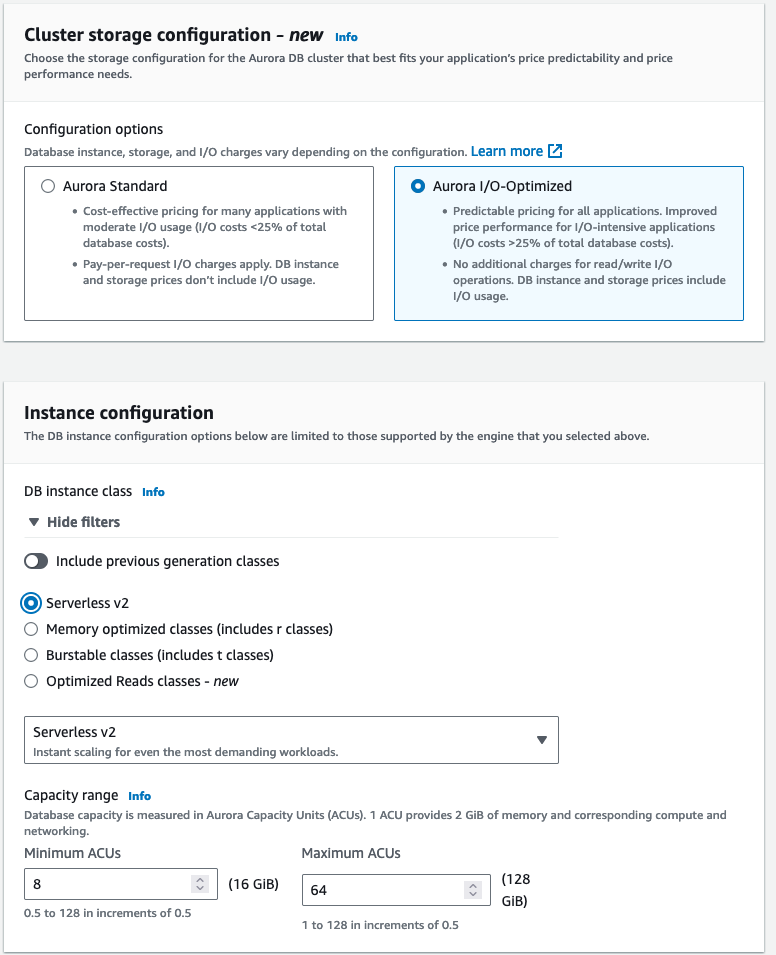
- Leave RDS Data API unchecked. We will not be using this feature.

- Create your Aurora cluster
Ingest documents from Amazon S3 into an Aurora PostgreSQL table
This step ingests your documents from an S3 bucket using the Boto3 library. Next, the function splits the documents into chunks using LangChain’s RecursiveCharacterTextSplitter. Lastly, the function uploads the chunks into an Aurora PostgreSQL table that you specify. The clean_chunk() function escapes special characters in the data to properly clean it before loading into the Aurora PostgreSQL table, which is a best practice because SQL functions can struggle with certain special characters.
Use the following Python code:
Create embeddings with SQL functions
A SQL procedure is created to select the text contents, generate embeddings from the text using the Amazon Titan Embeddings G1 – Text model (amazon.titan-embed-g1-text-02), and insert the embeddings into the table containing the original text. This model creates 1536-dimensional vector representations (embeddings) of unstructured text like documents, paragraphs, and sentences, taking up to 8,000 tokens as input.
The following code creates a PostgreSQL procedure that generates embeddings using the aws_bedrock.invoke_model_get_embeddings function. The model input is a JSON document. As a best practice, we recommend using the SQL format function to format the model input as given in the code.
Run a chatbot query to generate responses
The SQL function for generating responses to user questions performs the following tasks:
- Create an embedding of the user question using the same algorithm as the
generate_embeddings()function. Use best practices for formatting the model input. - Perform a similarity search, which is computationally efficient and works well for comparing directionally similar vectors like word and document embeddings. It compares the question embedding to existing content embeddings using a SQL SELECT statement. Return the text content with the closest match.
- Create a prompt and model input. The prompt provides instructions to the LLM and formats the question and similarity results using a Anthropic Claude prompt template. Include the prompt in the model input formatted as a JSON document using the SQL format function.
- Invoke the Anthropic Claude LLM on Amazon Bedrock (
anthropic.claude-instant-v1) to generate a natural language text response to the user question.
The similarity search and response generation are combined into a single function. This removes the need to call the similarity search separately from the application, reducing the overall latency of producing responses.
Use the following code:
Demonstration of using the chatbot
This AI-powered chatbot application offers multiple ways for users to ask questions. One option is for SQL developers to directly use SQL functions. We also developed a Python chatbot application using the Streamlit frontend framework. The code for this chatbot application is available on GitHub.
Upload your knowledge dataset to Amazon S3
We download the dataset for our knowledge base and upload it to an S3 bucket. This dataset will feed and power the chatbot. Complete the following steps:
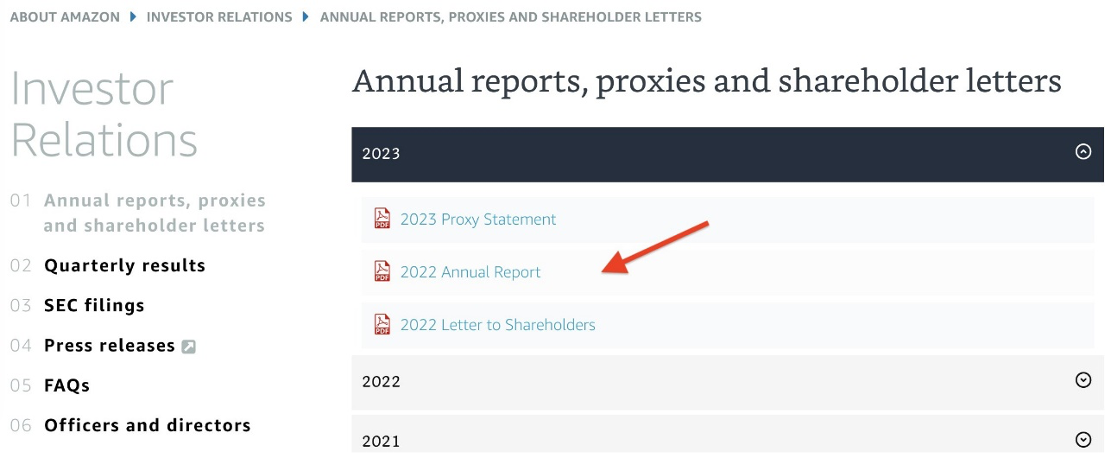
- Navigate to the Annual reports, proxies and shareholder letters data repository and download the last few years of Amazon shareholder letters.
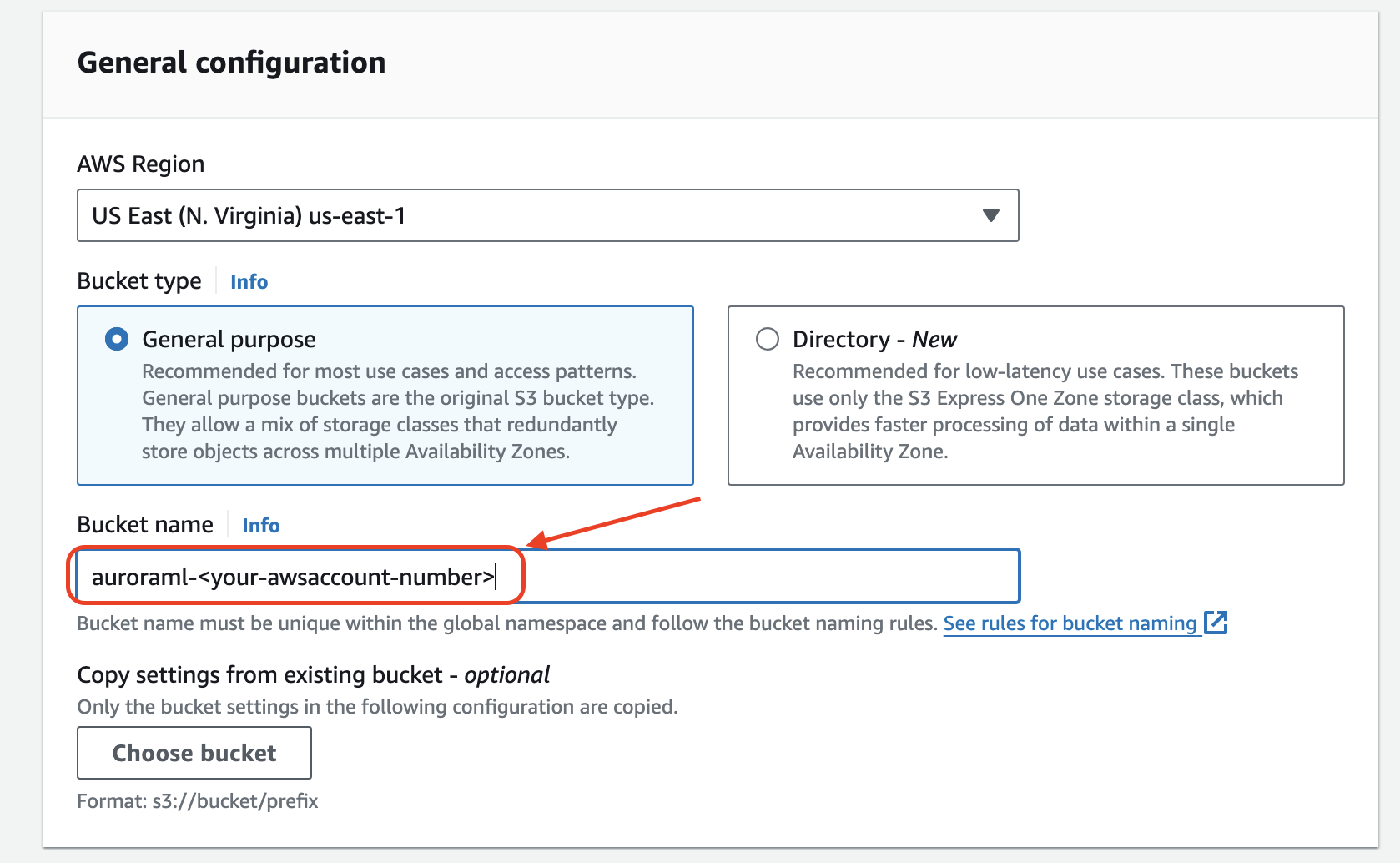
- On the Amazon S3 console, choose Create bucket.

- Name the bucket
auroraml-<your-awsaccount-number>.
- Leave all other bucket settings as default and choose Create.
- Navigate to the
auroraml-<your-awsaccount-number>bucket.

- Choose Upload.

- Upload the shareholder letters to the bucket.
Configure the chatbot application environment
The solution presented in this post is available in the following GitHub repo. You need to clone the GitHub repository to your local machine. Complete the following steps to configure the environment:
- Open a terminal window in AWS Cloud9 and run the following command (this is a single git clone command):
- Install Python packages:
- Configure environment variables used during the creation of the S3 bucket and Aurora PostgreSQL DB cluster. The following configurations are for demonstration only. For your production environment, refer to Security best practices for Aurora to securely configure your credentials.
- Configure the Aurora PostgreSQL pgvector and
aws_mlextensions, and a database table:
- Ingest documents and create embeddings:
Run using PostgreSQL
The following command allows you to connect to Amazon Aurora PostgreSQL using the psql client to ask a question and receive a response:

Run using Streamlit
The following command launches a Streamlit-powered, web-based interactive application. The application allows you to ask questions and receive answers using a user-friendly interface.
The configuration to open port 8080 is for demonstration only. For your production environment, refer to Protecting data in transit for best practices to securely expose your application.
The UI will look like the following screenshot. You can ask a question by entering the text in the Enter your question here field.

Clean up
To clean up your resources, complete the following steps:
- Delete the Aurora PostgreSQL DB cluster created as part of the demonstration.
- Delete the S3 bucket and the knowledge base dataset copied as part of the demonstration.
- If needed, disable access to FMs provided as part of prerequisites.
Conclusion
In this post, we demonstrated how you can use Aurora, Amazon Bedrock, and other AWS services to build an end-to-end generative AI chatbot application using SQL functions and Python. By storing text embeddings directly in Aurora, you can reduce latency and complexity compared to traditional architectures. The combination of Aurora ML, Amazon Bedrock FMs, and AWS compute like Amazon SageMaker provides a powerful environment for rapidly developing next-generation AI applications.
For more information, see Using Amazon Aurora machine learning with Aurora PostgreSQL.
About the Authors
 Naresh Dhiman is a Sr. Solutions Architect at Amazon Web Services supporting US federal customers. He has over 25 years of experience as a technology leader and is a recognized inventor with six patents. He specializes in containers, machine learning, and generative AI on AWS.
Naresh Dhiman is a Sr. Solutions Architect at Amazon Web Services supporting US federal customers. He has over 25 years of experience as a technology leader and is a recognized inventor with six patents. He specializes in containers, machine learning, and generative AI on AWS.
 Karan Lakhwani is a Customer Solutions Manager at Amazon Web Services supporting US federal customers. He specializes in generative AI technologies and is an AWS Golden Jacket recipient. Outside of work, Karan enjoys finding new restaurants and skiing.
Karan Lakhwani is a Customer Solutions Manager at Amazon Web Services supporting US federal customers. He specializes in generative AI technologies and is an AWS Golden Jacket recipient. Outside of work, Karan enjoys finding new restaurants and skiing.


