Configure Amazon EKS for environmental sustainability

Introduction
Sustainable cloud design requires understanding and minimizing the impacts of architectural decisions. With conscientious cloud architecture, we can innovate rapidly while treading lightly on our shared environment. As cloud computing becomes ubiquitous, it’s imperative that we build sustainable cloud architectures that minimize environmental impacts. While cloud economies of scale improve efficiency, our design choices determine the energy consumption and carbon emissions of cloud workloads. By selecting optimized services, right-sizing resources, and enabling autoscaling, architects can reduce the carbon footprint of cloud solutions.
In this post, we will focus on how to configure Amazon Elastic Kubernetes Service (Amazon EKS) for environmental sustainability. We will do this through the lens of the Sustainability Pillar of the AWS Well-Architected Framework.
The AWS Well-Architected Framework provides architectural best practices and strategies to build secure, high-performing, resilient, and efficient cloud applications on AWS. Sustainability is a key pillar of the AWS Well-Architected Framework as it ensures cloud architectures are designed and operated in an environmentally responsible manner. The sustainability pillar focuses on maximizing energy efficiency, reducing waste, and lowering carbon emissions associated with cloud workloads. By adopting sustainable practices, companies can build cloud architectures that use minimal resources to reduce their carbon footprint.
Solution overview
To efficiently run container workloads on Amazon EKS, we categorized our guidance into three main focus domains:
- Use managed services such as AWS Fargate for efficient operations
- Running efficient compute on Amazon Elastic Compute Cloud (Amazon EC2) instances serving as worker nodes
- Efficient data management practices for Amazon EKS
We will discuss tips and best practices that can help to optimize each of these pillars in Amazon EKS.
Walkthrough
Use AWS Fargate for efficient operation on Amazon EKS
SUS05-BP03 recommends using managed services to operate more efficiently in the cloud.
AWS Fargate as the compute option on Amazon EKS provides on-demand, right-sized compute capacity for containers as a managed service. With AWS Fargate, you don’t have to provision, configure, or scale groups of Amazon EC2 instances on your own to run containers. You also don’t need to choose server types, decide when to scale your node groups, or optimize cluster packing. You can control which Pods start on AWS Fargate and how they run with AWS Fargate profiles. AWS Fargate profiles are defined as part of your Amazon EKS cluster.
The benefits of AWS Fargate include:
- AWS Fargate enables you to focus on your applications. You define your application content, networking, storage, and scaling requirements. There is no provisioning, patching, cluster capacity management, or infrastructure management required.
- AWS Fargate supports all of the common container use cases including microservices architecture applications, batch processing, machine learning (ML) applications, and migrating on-premises applications to the cloud.
- Choose AWS Fargate for its isolation model and security. You should also select AWS Fargate if you want to launch containers without having to provision or manage Amazon EC2 instances and reduce operational overhead.
Running efficient compute on Amazon EC2 instances serving as worker nodes
Use the latest version of Kubernetes on Amazon EKS
Following the Sustainability pillar best practice SUS06-BP02 – Keep your workload up-to-date, enables easier adoption of efficient technologies and features. Use the latest version of Kubernetes on Amazon EKS to improve the overall efficiency of your container workload.
Refer to the Amazon EKS Best Practices Guide for details on how to manage your upgrades on your control and data planes.
Updating Kubernetes versions may introduce significant changes. We recommend that you test your applications against a new Kubernetes version before you update your production clusters. You can do this by building a Continuous Integration workflow to test your application before moving to a new Kubernetes version. More details in the Amazon EKS User Guide.
In order to help with Amazon EKS cluster upgrades using Infrastructure as Code tools such as Terraform, look into deploying your new clusters via EKS Blueprints. There are instructions around Amazon EKS cluster upgrades and the use of Managed Node Groups that will help with creating, automatically updating, and terminating nodes for your cluster with a single operation.
Use Karpenter for cluster autoscaling
SUS05-BP01 encourages using the minimum amount of hardware to meet your needs and using horizontal scaling and automation to scale out your workloads.
If running Amazon EKS on AWS Fargate as your compute isn’t an option for your workload, then you can consider running Amazon EC2 instances on EKS with Karpenter.
Karpenter is an open-source node provisioning project built for Kubernetes. Adding Karpenter to a Kubernetes cluster can dramatically improve the efficiency of running workloads on that cluster.
Karpenter’s objective is to make sure that your cluster’s workloads have the compute they need, no more and no less, right when they need it, without having to use Auto Scaling Groups. In addition, Karpenter makes it easy to adopt the wide range of compute options we have in AWS, including Graviton and Spot instances which enhance sustainability for your Amazon EKS clusters and hosts.
Karpenter works by configuring NodePools that define node provisioning constraints and de-provisioning behaviors as described in the following details:
- Watching for pods that the Kubernetes scheduler has marked as unschedulable
- Evaluating scheduling constraints (i.e., resource requests, node selectors, affinities, tolerations, and topology spread constraints) requested by the pods
- Provisioning nodes that meet the requirements of the pods
- Removing the nodes when the nodes are no longer needed.
Use instance types with least impact for EKS cluster
SUS05-BP02 recommends using instance types with least impact. This includes transitioning your workload to Graviton-based instances to improve performance efficiency of your workload. AWS Graviton-based instances offer the best performance per watt of energy use in Amazon EC2 instance types. Graviton3-based instances use up to 60% less energy for the same performance than comparable Amazon EC2 instances.
Using Karpenter, you can configure the NodePool to select from ARM or AMD-based processors as shown in the following code example. You can look for further details in the Karpenter documentation around configuring NodePools.
If you have ML (Machine Learning) use cases such as training natural language processing, computer vision, and recommender models, then look into using AWS Trainium. It’s the second-generation ML chip that AWS purpose built for deep learning training. AWS Trainium-based EC2 Trn1 instances delivers faster time to train deep learning models while offering up to 50% cost-to-train savings over comparable GPU-based instances.
You can run large-scale containerized training jobs within Amazon EKS while taking full advantage of the price-performance, scalability, and maximisation of CPUs with Trn1 instances. For more information around how to configure this solution, refer to the Scaling distributed training with AWS Trainium and Amazon EKS post.
What about for deep learning inference applications running on Amazon EKS? You can achieve 2.3-fold higher throughput and up to 70% lower cost per inference compared to the Amazon EC2 instances by creating nodes running AWS Inferentia on Amazon EKS.
Use right capacity type for your instances
SUS05-BP02 also encourages using Amazon EC2 Spot instances for stateless, fault-tolerant and flexible workloads to increase overall utilization of the cloud and reduce the sustainability impact.
You can use either Spot, On-Demand Instances, or both for configuring NodePools in Karpenter. When you specify both, and if the pod doesn’t explicitly specify whether it needs to use Spot or On-Demand, then Karpenter opts to use Spot when provisioning a node.
If the Spot capacity isn’t available, then the general best practice is to allow Karpenter to use a diverse set of instance types when using Spot. You can view Karpenter Best Practices for configuring to prepare for Spot interruptions.
Configure efficient placement for your Amazon EKS cluster
SUS02-BP04 recommends placing your workload close to your customers to provide the lowest latency while decreasing data movement across the network and lowering environmental impact.
Amazon CloudFront can be used with Application Load Balancers for your Amazon EKS cluster. Amazon CloudFront caches assets being served from the origin sources, which may reduce bandwidth requirements depending on what you are serving. In addition, AWS Global Accelerator can help route workloads to the nearest region based on request IP address. This may be useful for workloads that are deployed to multiple regions.
Use pod allocation strategies that minimize idle resources
Best practice SUS05-BP01 recommends mechanisms that minimizes the average resources required per unit of work. Karpenter uses an online bin-packing algorithm based on a batch interval to create the right-sized Amazon EC2 instances for your workload based on the aggregated CPU and Memory requests for the pods in that batch.
This is based on the CPU, memory, and GPUs required, taking into account node overhead, Virtual Private Cloud (VPC) Container Network Interface (CNI) resources required, and daemonsets that will be packed when bringing up a new node.
If you are using the On-Demand capacity type, then Karpenter uses the lowest-price allocation strategy, which is based on the Price Capacity Optimized allocation strategy. For the Spot capacity type, the Amazon EC2 fleet application programming interface (API) determines an instance type with the lowest price with the lowest chance of being interrupted.
Use workload consolidation
Best practice SUS03-BP02 recommends removing components that are unused and no longer required and consolidate other underutilised components with other resources for improving efficiency.
As the workloads in an Amazon EKS cluster change and scale, it can be necessary to launch new Amazon EC2 instances to ensure they have the compute resources they need. Over time, those instances can become under-utilized as some workloads scale down or are removed from the cluster. Workload consolidation for Karpenter automatically looks for opportunities to reschedule these workloads onto a set of more cost-efficient Amazon EC2 instances, whether they are already in the cluster or need to be launched.
You can use expiration on provisioned nodes to set when to delete nodes that are devoid of workload pods or have reached an expiration time. Node expiry can be used for upgrades, so that nodes are retired and replaced with updated versions. More details here around node expiration.
Monitor and right-size compute resources
SUS05-BP01 recommends to use the minimum amount of hardware for your workload to efficiently meet your business needs by monitoring your resource utilization.
Use Amazon CloudWatch Container Insights to see how you can use native Amazon CloudWatch features to monitor your Amazon EKS Cluster performance. You can use Amazon CloudWatch Container Insights to collect, aggregate, and summarize metrics and logs from your containerized applications and microservices running on Amazon EKS. The metrics include utilization for resources such as CPU, memory, disk, and network — which can help with right-sizing Pods.
The Kubernetes dashboard provides resource usage breakdowns for each node and pod, as well as detailed metadata about pods, services, Deployments, and other Kubernetes objects. This consolidated information provides visibility into your Kubernetes environment.
Right-sizing in Kubernetes means setting the right compute resources (CPU and memory are collectively referred to as compute resources) to each pod. This means setting the resource requests that align as close as possible to the actual utilization.
A tool like kube-resource-report is valuable at visualizing the actual resource usage for the containers in a pod.
The right size guide (rsg) is a simple Command Line Interface (CLI) tool that provides you with memory and CPU recommendations for your application. This tool works across container orchestrators, including Kubernetes and easy to deploy.
Goldilocks is another option for an open-source tool which helps with optimising resource allocation and right-sizing applications in Kubernetes environments.
Kubecost also provides you with visibility into spend and resource efficiency in Kubernetes environments. You can automate request right-sizing via Kubecost by integrating this with your continuous integration and continuous delivery/deployment (CI/CD) pipelines.
You can deploy an Amazon EKS-optimized bundle of Kubecost for cluster cost visibility. This is available free of charge, and customers can get Kubecost support from AWS as part of their existing AWS support agreements. Kubecost enables users to view costs broken down by Kubernetes resources including pods, nodes, namespaces, labels, and more. Kubernetes platform administrators and finance leaders can use Kubecost to visualize a breakdown of their Amazon EKS charges, allocate costs, and chargeback organizational units (e.g., application teams). Customers can provide their internal teams and business units with transparent and accurate cost data based on their actual AWS bill and get customized recommendations for cost optimization based on their infrastructure environment and usage patterns within a single cluster.
There is a variety of options within Kubecost such as right-sizing your container requests for CPU and Memory utilization to managing underutilized nodes to resizing local disks.
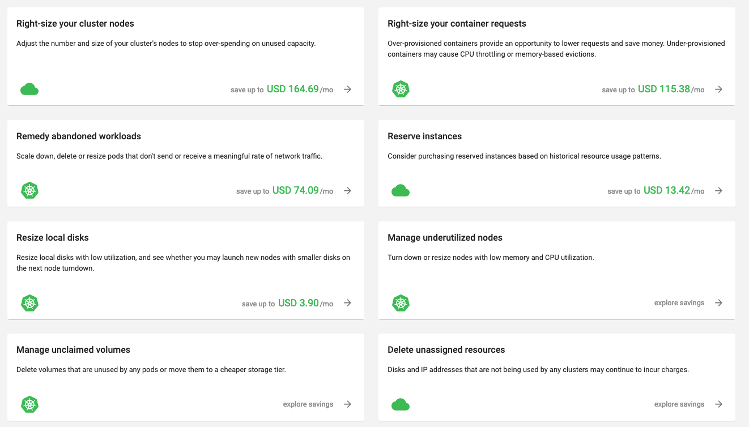
AWS Trusted Advisor and AWS Compute Optimizer also provides recommendations around compute right-sizing. To right-size your Amazon EKS nodes, AWS Compute Optimizer helps you identify the optimal Amazon EC2 instance types and Amazon Elastic Block Store (Amazon EBS) volume configurations.
Use Limit Ranges and Resource Quota policies to constrain the amount of resource consumptions
SUS05-BP01 recommends using the minimum amount of hardware recommended to run your workloads.
By default, there are no limits on compute resources used by containers on an Amazon EKS cluster. To restrict spike in resource consumption, use Resource Limit Ranges and Resource Quotas policies for your Amazon EKS cluster.
A Limit Range policy constrains the resource allocations for Pods or containers in a namespace while Resource Quotas set limit for the total amount of memory and CPU that can be used by containers in a namespace.
Efficient data management practices for Amazon EKS
When considering how to architect your Amazon EKS applications for sustainability, it’s important to choose the correct data storage medium. Based on SUS-4-BP02, use storage technologies that best supports how your data is accessed and stored to minimize the resources provisioned while supporting your workload.
Use shared storage (optional)
First, it’s important to determine whether you need storage at all. For many web applications, session data is stored on the client side. These stateless applications don’t require sharing files between pods. If possible, then you should architect your application to be stateless, as these types of applications are more flexible, easier to scale, and consume fewer resources.
Stateful applications include content management, developer tools, as well as ML frameworks and shared notebook systems. For these types of applications, it is recommended to use shared storage (SUS04-BP06).
In Amazon EKS persistent storage volumes are backed by AWS services, including Amazon EBS, Amazon Elastic File System (Amazon EFS), and Amazon FSx.
You can also use services such as Amazon Relational Database Service (Amazon RDS), Amazon ElastiCache, and Amazon MSK to store your data if your applications are stateful.
SUS04-BP02 recommends understanding your use-case and access patterns to choose the correct storage type.
The following guidance will help you choose the correct storage type for Amazon EKS.
Use Amazon EFS for general use cases
Use Amazon EFS for general use cases with Linux containers. Amazon EFS can help you avoid over-provisioning issues when using block storage and has lifecycle policies to enable deletion and archival of unused data (SUS04-BP03 and SUS04-BP04). Amazon EFS can be configured for Amazon EKS using the Amazon EFS CSI Driver.
Use SMB CSI Driver for Windows Containers
The Amazon EFS CSI Driver isn’t compatible with Windows-based container images. Instead, you can use the SMB CSI driver with Amazon FSx for Windows to add storage to your Windows-based Amazon EKS pods.
Best practices:
Use Amazon EBS for non-shared storage and low latency use cases
You should consider using Amazon EBS CSI for use cases that don’t require shared storage or require very low latency. Examples include databases and sharded clusters like Apache Kafka.
Best practices:
| Storage type | Shared? | Supports CSI driver? | Use case |
| Amazon EFS | Yes | Yes | General Purpose shared storage use cases |
| Amazon EBS | No | Yes | Databases, sharded clusters |
| Amazon FSx for Windows | Yes | Yes* | Windows Containers |
| Amazon FSx For Lustre | Yes | Yes | High Performance Compute (HPC) |
| *Amazon FSx for Windows is supported on Amazon EKS clusters with Windows Support enabled | |||
Consider object storage
Filesystems, such as Amazon EFS and Amazon FSx, are good for files that need to be frequently accessed. If you have data that is accessed infrequently, you can store it in Amazon Simple Storage Service (Amazon S3) and use Amazon S3’s lifecycle management features to move it to a lower-impact storage class when it is no longer needed (SUS04-BP03). By using the Mountpoint for Amazon S3 Container Storage Interface (CSI) driver, your Kubernetes applications can access Amazon S3 objects through a file system interface, achieving high aggregate throughput without changing any application code. You can avoid the types of over-provisioning issues you would encounter with block-based storage and filesystems.
Collect appropriate metrics
Selecting the appropriate storage metrics for your workload is crucial to sustaining your Amazon EKS application over time. Each storage option offers different metrics to track the resource usage of your workload. Make sure you’re monitoring against any storage burst metrics (e.g., burst credits for Amazon EFS). For storage systems that are fixed sized, like Amazon EBS or Amazon FSx, monitor the amount of storage used compared to the overall storage size. All the above-mentioned services publish metrics to Amazon CloudWatch, which you can use to create dashboards to monitor usage and create alarms.
This table shows you useful metrics to track for each storage type:
| Storage type | Metrics to track |
| Amazon EFS | Throughput utilization, IOPS utilization, Burst credit balance |
| Amazon EBS | BurstBalance, VolumeReadBytes, VolumeWriteBytes |
| Amazon FSx | FreeStorageCapacity, DataReadBytes, DataWriteBytes |
Minimize data movement
Caching can be used to minimize data movement across networks (SUS04-BP07). For web applications hosted on Amazon EKS, you can use a Content Delivery Network such as Amazon CloudFront to cache application data closer to your users. You can use Amazon CloudFront to automatically compress and serve objects when viewers (i.e., web browsers or other clients) support them. Viewers indicate their support for compressed objects with the “Accept-Encoding” HTTP header.
If you’re using Amazon EKS version 1.24 and later versions, then Topology Aware Hints are enabled by default to keep traffic within the same Availability Zone (AZ) for worker nodes, which are deployed across multiple AZs.
You can also set inter-pod affinity and anti-affinity, which will allow you to run pods on a node based on whether certain pods are running or not running that helps with scheduling and minimising data movement.
You can also configure node affinity to have your pod run on nodes that have node selector terms matching a particular AZ. More details on how to configure this using Karpenter here.
Conclusion
In this post, we have provided guidance and best practices to help optimize your Kubernetes workload on AWS through configuring Amazon EKS. All of these recommendations demonstrate best practices from the Sustainability Pillar of the AWS Well-Architected Framework.
You can refer to the below section “Further reading” to apply additional best practices to your Amazon EKS workloads. Please feel free to leave a comment in the feedback form below.
Further reading:



