GPT trains robots better than humans – as proven by this dog on a yoga ball

DrEureka, a new open-source software package that anyone can play with, is used to train robots to perform real-world tasks using Large Language Models (LLMs) such as ChatGPT 4. It’s a “sim-to-reality” system, meaning it teaches the robots in a virtual environment using simulated physics, before implementing them in meatspace.
Dr Jim Fan, one of the developers of DrEureka, deployed a Unitree Go1 quadruped robot to bounce its way into the headlines. It’s a “low-cost” and well-supported open-source robot – which is handy, because even with AI, robo-pets are still susceptible to fall damage. As for “low cost,” well… It’s listed on Amazon for $5,899 USD and has a 1-star rating – take that as you may.
We trained a robot dog to balance and walk on top of a yoga ball purely in simulation, and then transfer zero-shot to the real world. No fine-tuning. Just works.
I’m excited to announce DrEureka, an LLM agent that writes code to train robot skills in simulation, and writes more… pic.twitter.com/kuG14LmSOh
— Jim Fan (@DrJimFan) May 3, 2024
The “Dr” in DrEureka stands for “Domain randomization” – as in randomizing variables such as friction, mass, damping, center of gravity, etc in a simulated environment.
With a few prompts into an LLM like ChatGPT, the AI can write code that creates a reward/penalty system to train the bot in virtual space, where 0 = fail, and anything higher than 0 is a win. The higher the score the better.
It can create parameters by minimizing and maxing out failure/break points in areas such as bounciness of ball, motor strength, degree of freedom in its limbs, and damping to name a few. As an LLM, it has no problem creating these in huge volumes, for the training system to run concurrently.
After each simulation, GPT can also reflect on how well the virtual robot did, and how it can improve. Exceeding or violating parameters, say, by overheating a motor or attempting to articulate a limb beyond its capabilites, will result in a 0… And no one likes to score zero points, not even an AI.
Eureka Research
Prompting an LLM to write the code requires safety instruction – otherwise, the team found GPT will strive for the best possible performance – and basically ‘cheat’ in the simulation without guidance. That’s fine in a simulation, but in real life it could overheat motors, or over-extend limbs, damaging the robot – the researchers call this phenomenon “degenerate behavior.”
In one example of its self-taught unnatural behavior, the virtual robot discovered it move more quickly by thrusting its hip into the ground and using three feet to scurry across the floor while dragging its hip. This paints a somewhat disturbing picture in my mind, to be honest – but of course, while this was an advantage in the simulation, it resulted in an unproductive faceplant when the robot attempted it in the real world.
So the researchers instructed GPT to be extra careful, bearing in mind that the robot would be tested in the real world –and in response, GPT created safety functions for things like smooth action, torso orientation, torso height and making sure the robot’s motors weren’t over-torqued. Should the robot cheat and violate these parameters, its reward function would offer a lower score. Safety functions mitigate degenerate and unnatural behaviors – you know, like unnecessary pelvic thrusts.
So how did it perform? Better than us. DrEureka was able to beat humans at training the robo-pooch, seeing a 34% advantage in forward velocity and 20% in distance traveled across real-world mixed terrains.
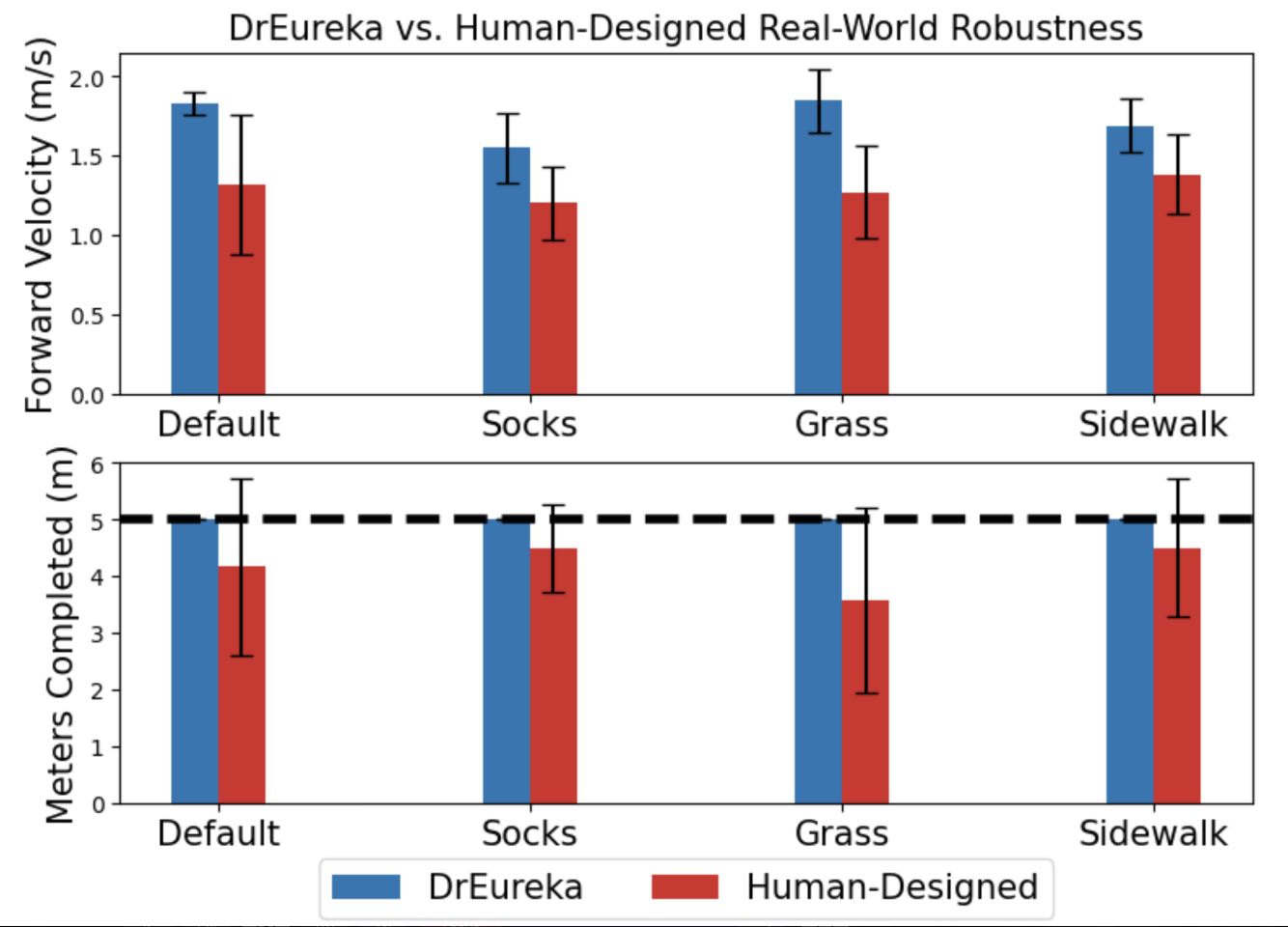
Eureka Research
How? Well, according to the researchers, it’s all about the teaching style. Humans tend towards a curriculum-style teaching environment – breaking tasks down into small steps and trying to explain them in isolation, whereas GPT has the ability to effectively teach everything, all at once. That’s something we’re simply not capable of doing.
DrEureka is the first of its kind. It’s able to go “zero-shot” from simulation to real-world. Imagine having almost no working knowledge of the world around you and being pushed out of the nest and left to just figure it out. That’s zero-shot.
The creators of DrEureka believe they could further improve on the sim-to-reality training if they could provide real-world feedback to GPT. Currently, all sim training is done using data from the robot’s own proprioception systems, but if GPT could actually see what went wrong through a real-world video feed rather than merely reading the execution-failure in the robot’s logs, it could refine its instructions much more effectively.
It takes the average human up to a year and a half to learn to walk, and I’d wager only a tiny fraction of 1 percent of humans can do so atop a yoga ball. And why a yoga ball, you ask? They were inspired by the circus, of course. Aren’t we all?
You can watch an uncut 4 mins and 33 second video of robo-dog going for a walk on a yoga ball without a single stop to pee on a hydrant here:
DrEureka 5-minute Uncut Deployment Video
Source: Eureka Research



