How Datasaur Reimagines Data Labeling Tasks Using Generative AI on AWS

By Ivan Lee, CEO – Datasaur
By Kruthi Jayasimha Rao, Partner Solutions Architect – AWS
| Datasaur |
 |
Generative artificial intelligence (AI) is one of the most rapidly advancing fields in technology. Models have exponentially increased in scale, with parameters growing from billions to hundreds of billions, capturing complex patterns and relationships in data while generating new content.
Based on an Amazon Web Services (AWS) and Altman Solon 2023 survey, adoption of generative AI will grow significantly over the next two years. This growth is driving a significant rise of generative AI applications within natural language processing (NLP) such as data labeling, data augmentation, and question answering.
Traditionally, NLP projects have relied on human expertise and labor to generate labeled training data. Common approaches involve domain experts manually analyzing text to apply part-of-speech tags, entity labels, and other semantic annotations. While effective for many tasks, traditional methods struggle with the massive data needs of modern deep learning systems.
Today, there’s a growing need for generative AI to help with data labeling as machine learning (ML) models require enormous amounts of high-quality annotated data for training. However, manually labeling data at that scale is time-consuming and labor-intensive.
Generative AI models automatically create large synthetic (yet realistic) datasets to address the lack-of-data problem. They support updating data over time as needs change, without restarting the labeling process from scratch. As AI systems progress, generative capabilities are crucial to scale data collection and keep pace with the massive annotation demands of the future.
To address these challenges, AWS has collaborated with Datasaur, an AWS Partner and AWS Marketplace Seller that offers end-to-end data labeling NLP and large language model (LLM) solutions on AWS. Datasaur solutions integrate with AI/ML services like Amazon SageMaker, Amazon Comprehend, Amazon Textract, and more.
Data Labeling Challenges
While generative AI shows promise for scalably synthesizing labeled data, there remain significant challenges to address before reliably replacing human effort. With hundreds of large language models—and no one LLM fits all scenarios—questions arise, such as
- How to automate annotation tasks?
- How to include human feedback to improve model outputs?
- Which is the right model for a particular use case?
- How to evaluate multiple model responses?
- What is the cost implication of using these models?
- How is the model performing?
- How to combine generative AI with traditional NLP methods?
In the following sections, we see how Datasaur’s solutions address these challenges.
Solution Overview
Datasaur helps machine learning teams manage their labeling workforce and improve the quality of their training data, while enabling companies to take raw data and label it for ML model consumption.
Datasaur’s NLP Platform is a comprehensive solution for text, documents, and audio data. Its configurable interface supports all forms of NLP, from entity recognition and sentiment analysis to more advanced techniques such as coreference resolution and dependency parsing.
The solution supports annotation workforce management at scale, incorporating powerful review capabilities and automatically capturing inter-annotator agreement to track team efficiency and remove human error and bias from training datasets.
A major trend in recent years has been applying automation to annotation tasks. As companies scale their efforts and track their budgets, it’s imperative to build upon existing solutions when it comes to labeling data.
Datasaur integrates with popular libraries such as spaCy and NLTK to automatically detect solved entity classes like names of people, organizations, and dates. It also incorporates weakly supervised learning, allowing data scientists to write and apply labeling functions and heuristics. Such methods save users between 20-70% of their time and resources.
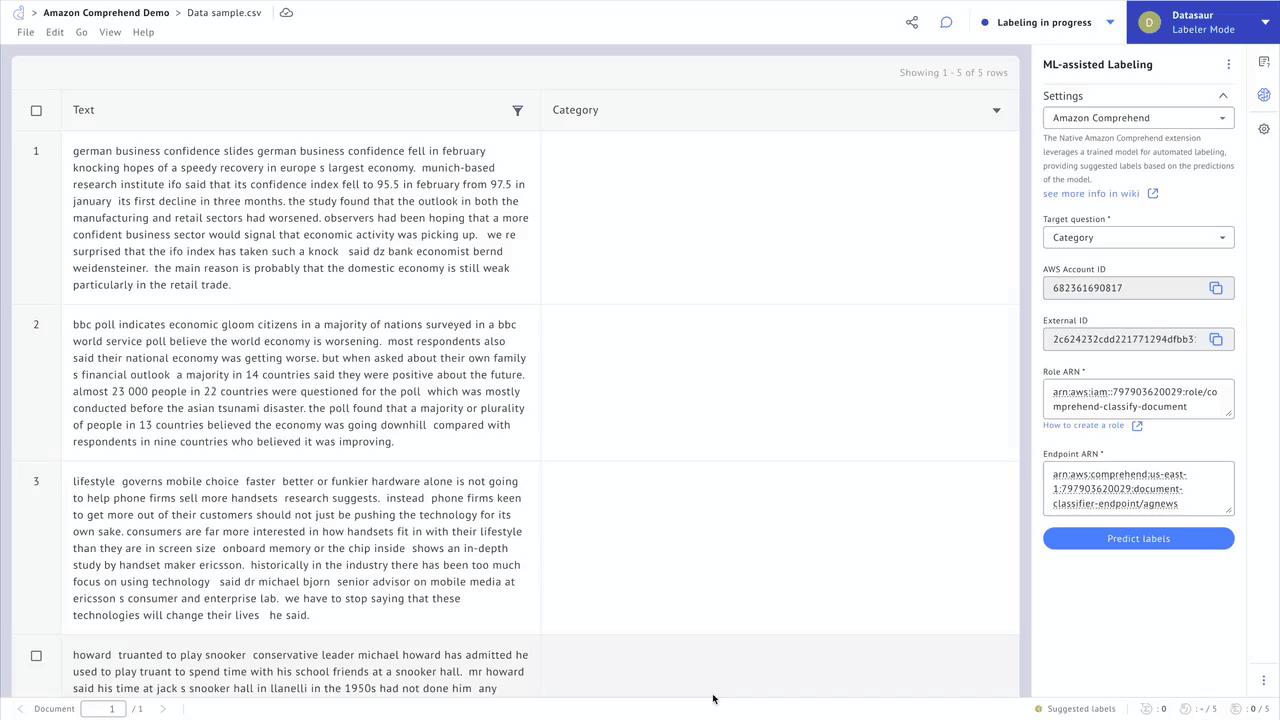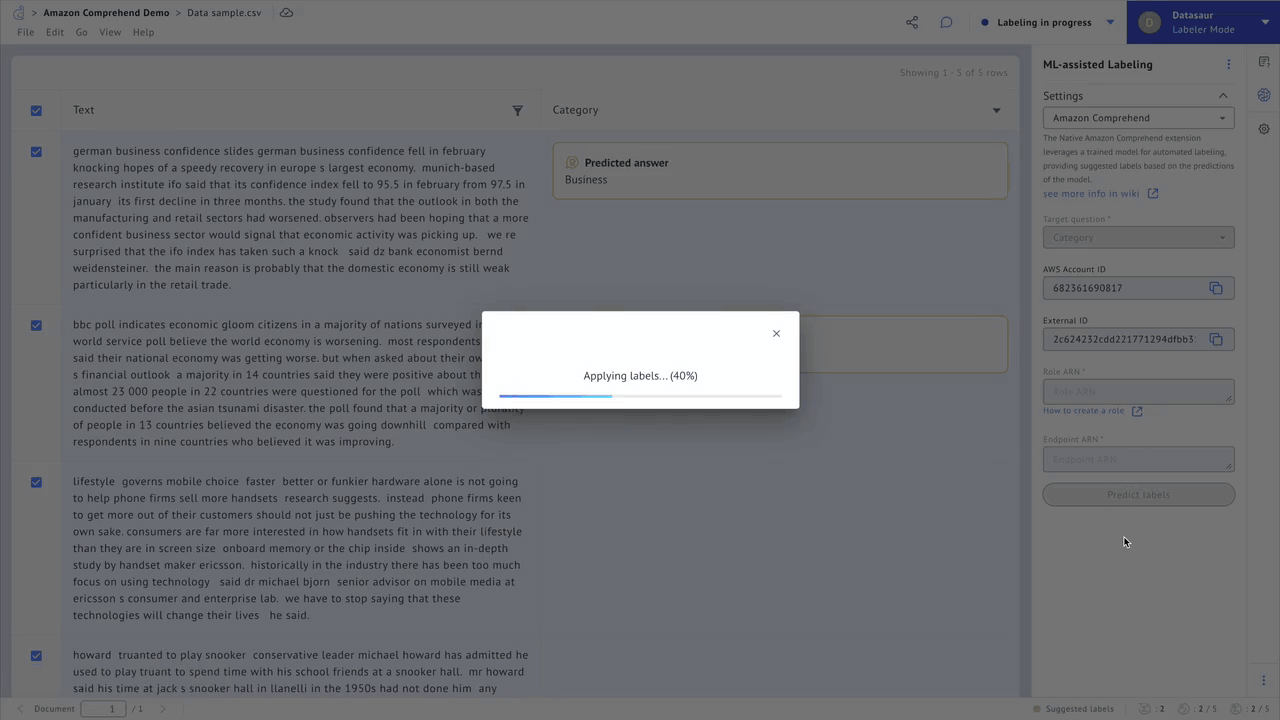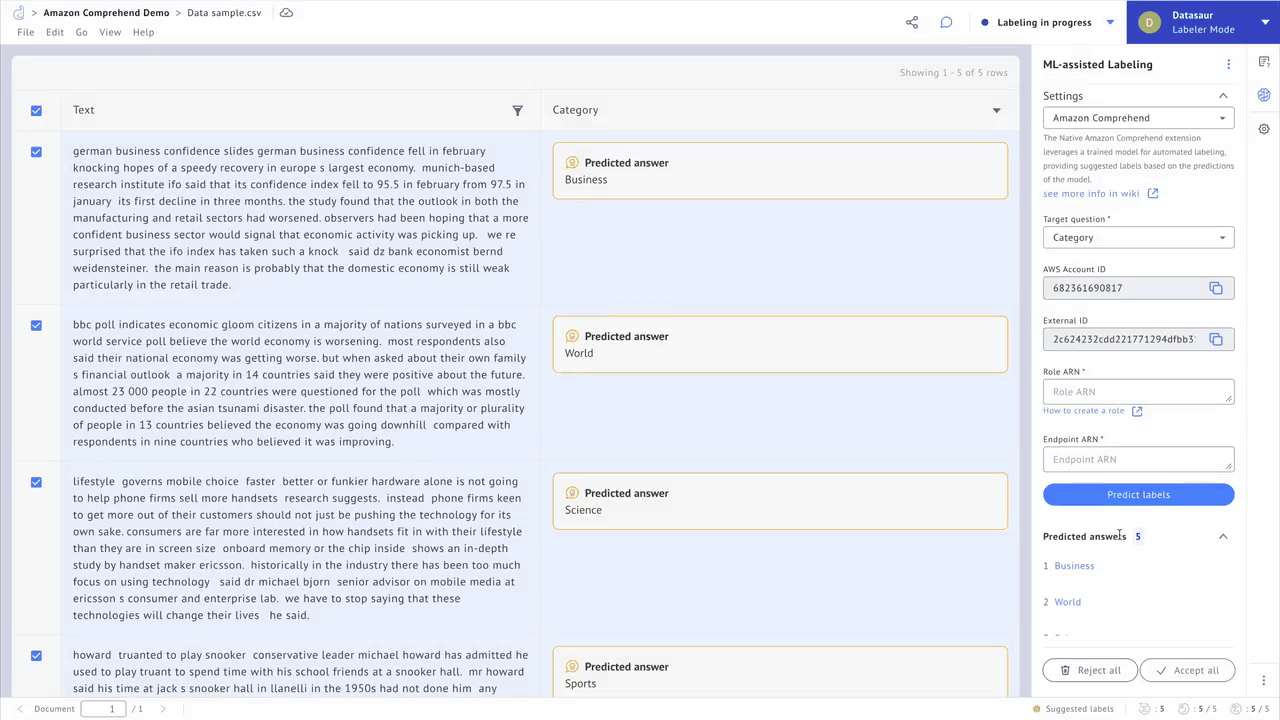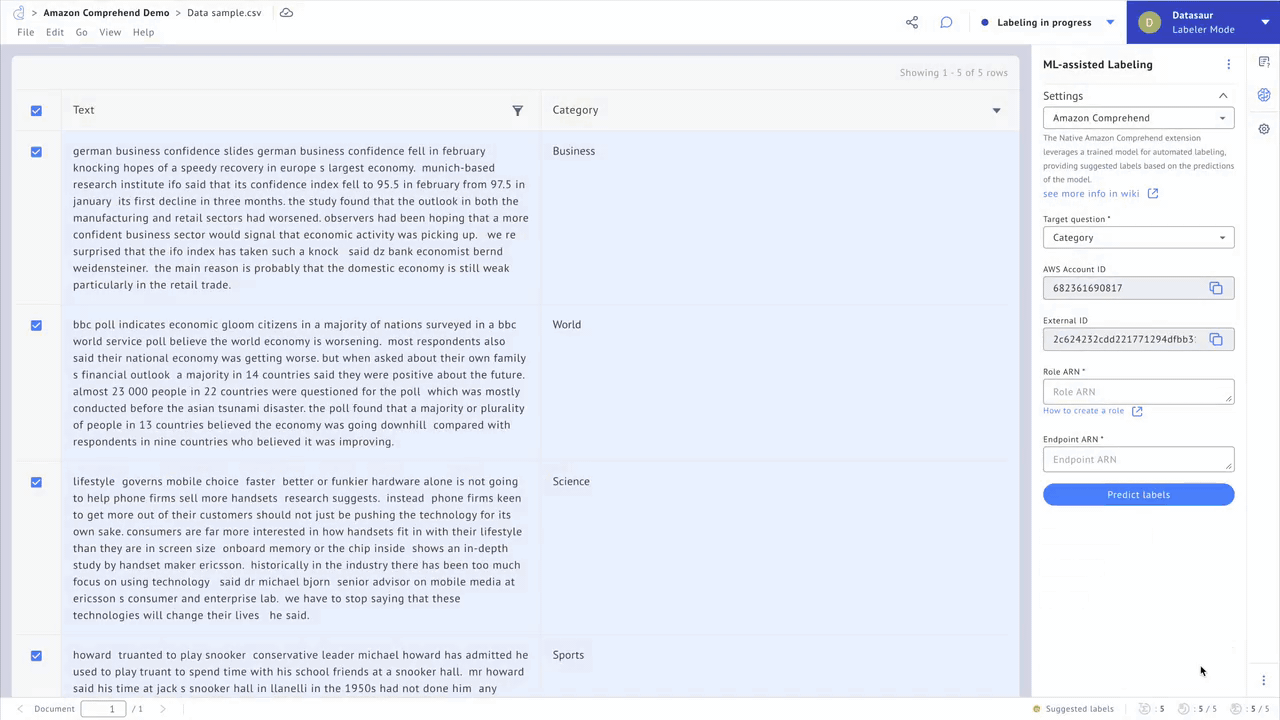
Figure 1 – Automate annotation tasks.
A majority of Datasaur’s customers are also on AWS, and the NLP Platform supports deep integrations. It connects directly to Amazon Simple Storage Service (Amazon S3) buckets, allowing automated ingestion of data into data labeling projects.
Labeled data can similarly be exported into S3 buckets in an Amazon SageMaker-ready format for model training. Further integration with Amazon Textract allows for instant optical character recognition (OCR) capabilities for images and PDFs containing text data.
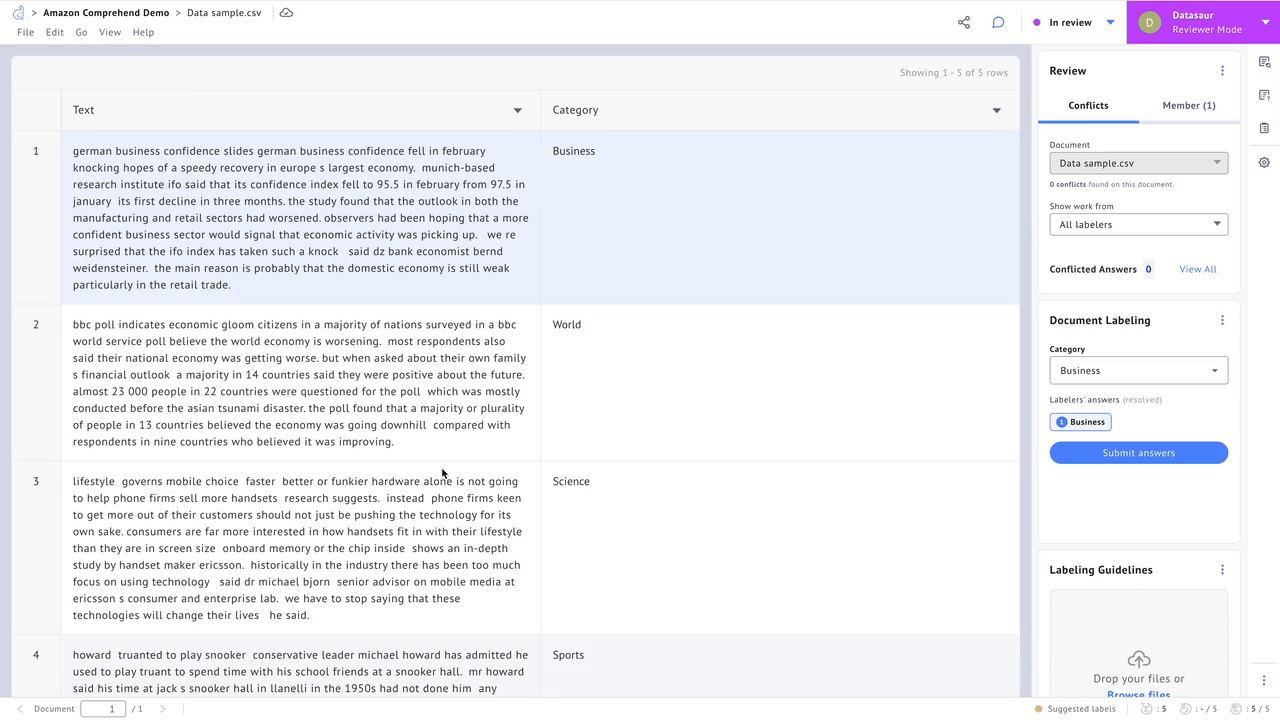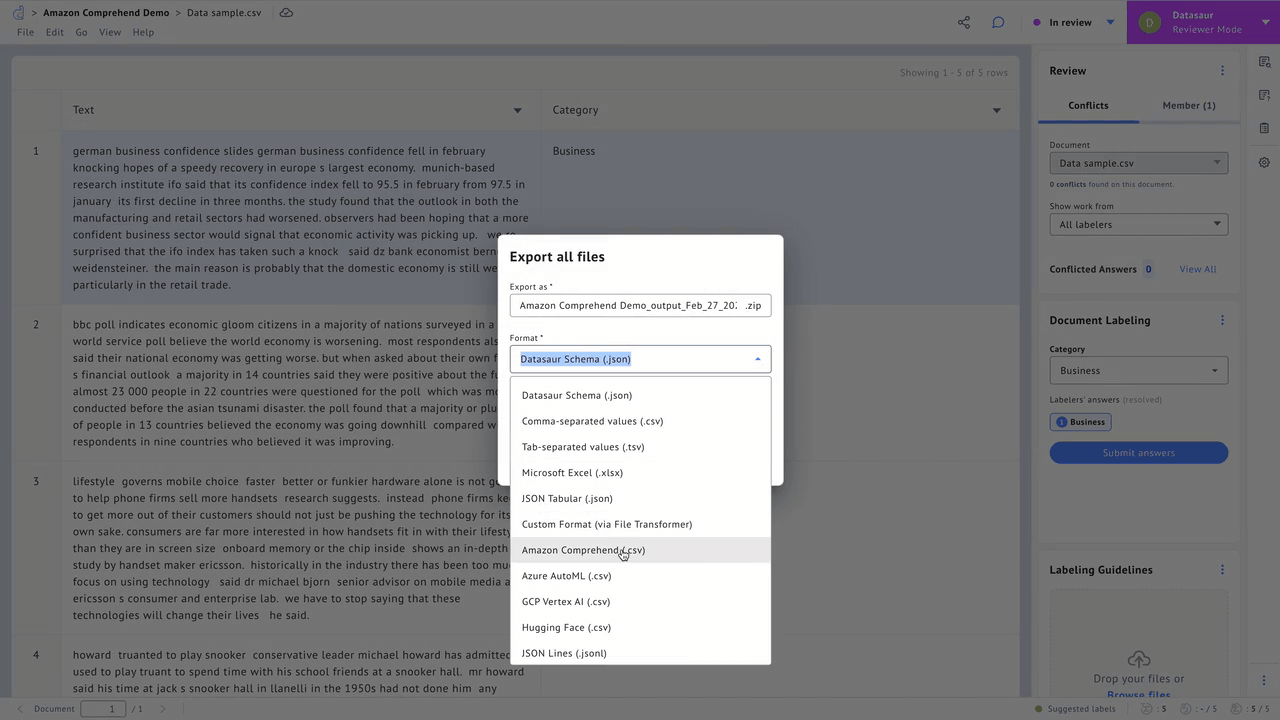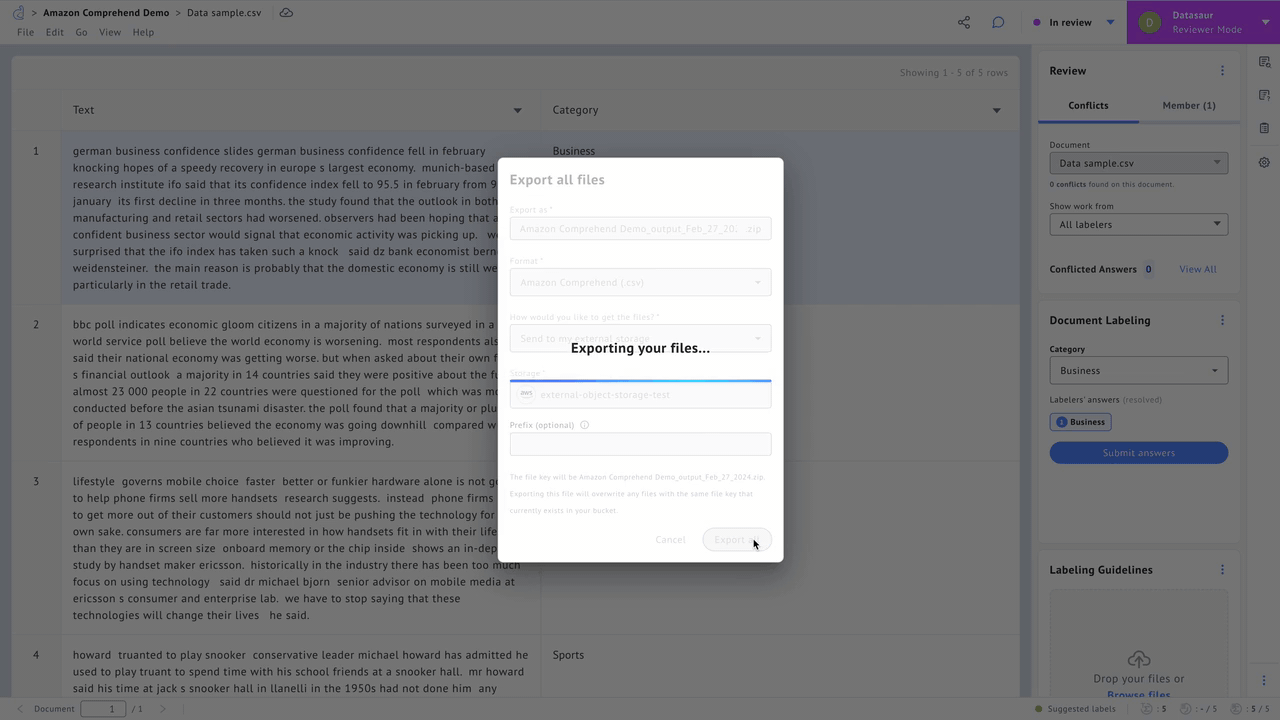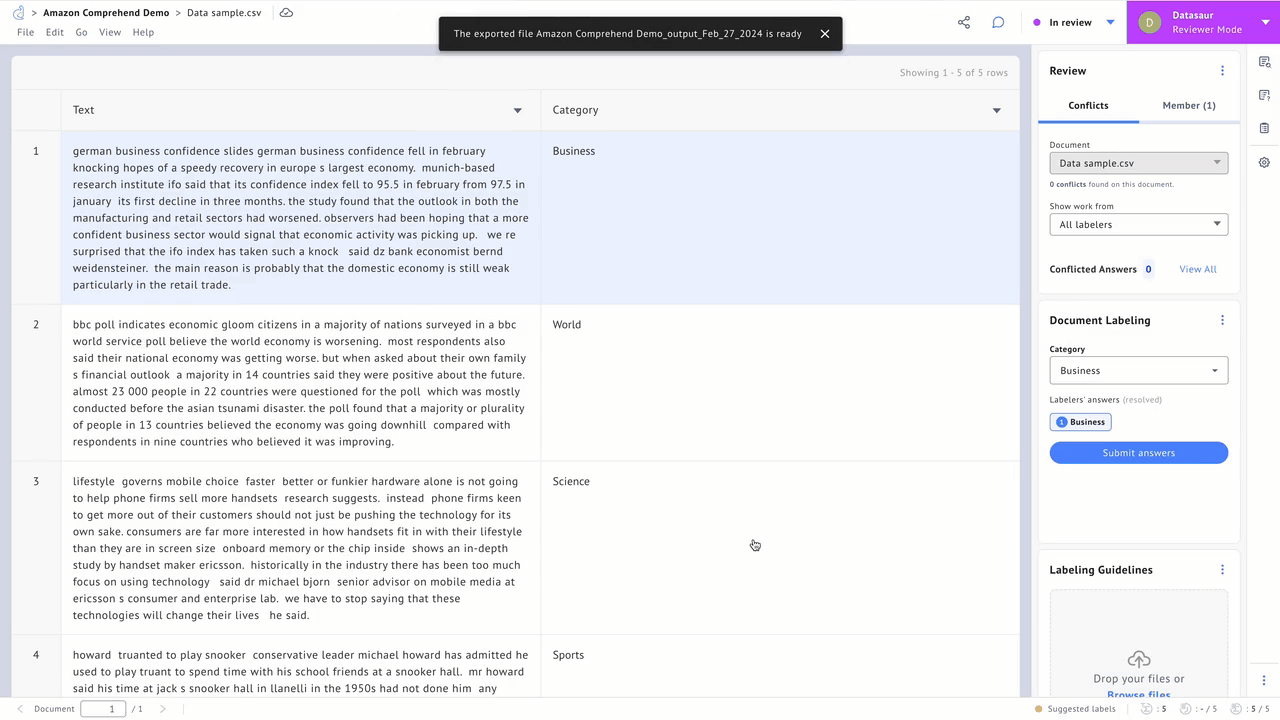
Figure 2 – Export labeled data.
Advanced Capabilities with LLM Labs
With large language models, data scientists have been quick to experiment with using generative AI’s powerful predictive capabilities for data labeling purposes. It can be confusing to understand which models excel at specific tasks, and applying proprietary LLMs can quickly rack up bills when applying labels to data at scale.
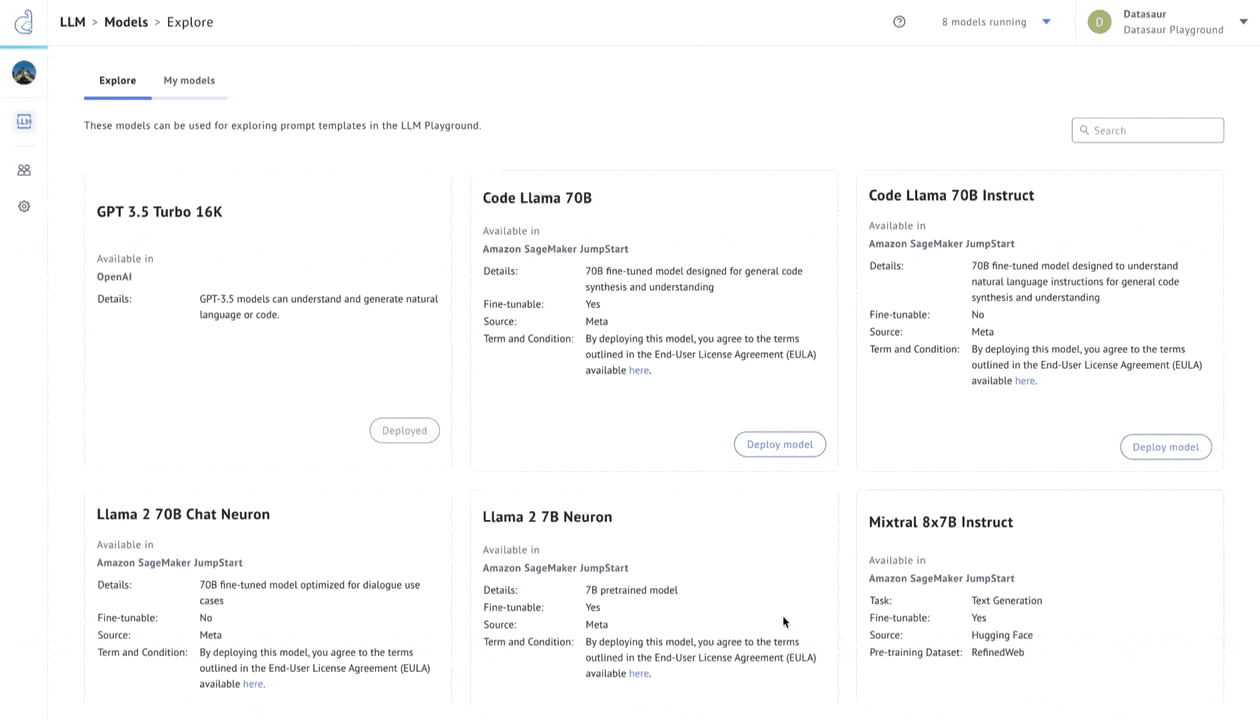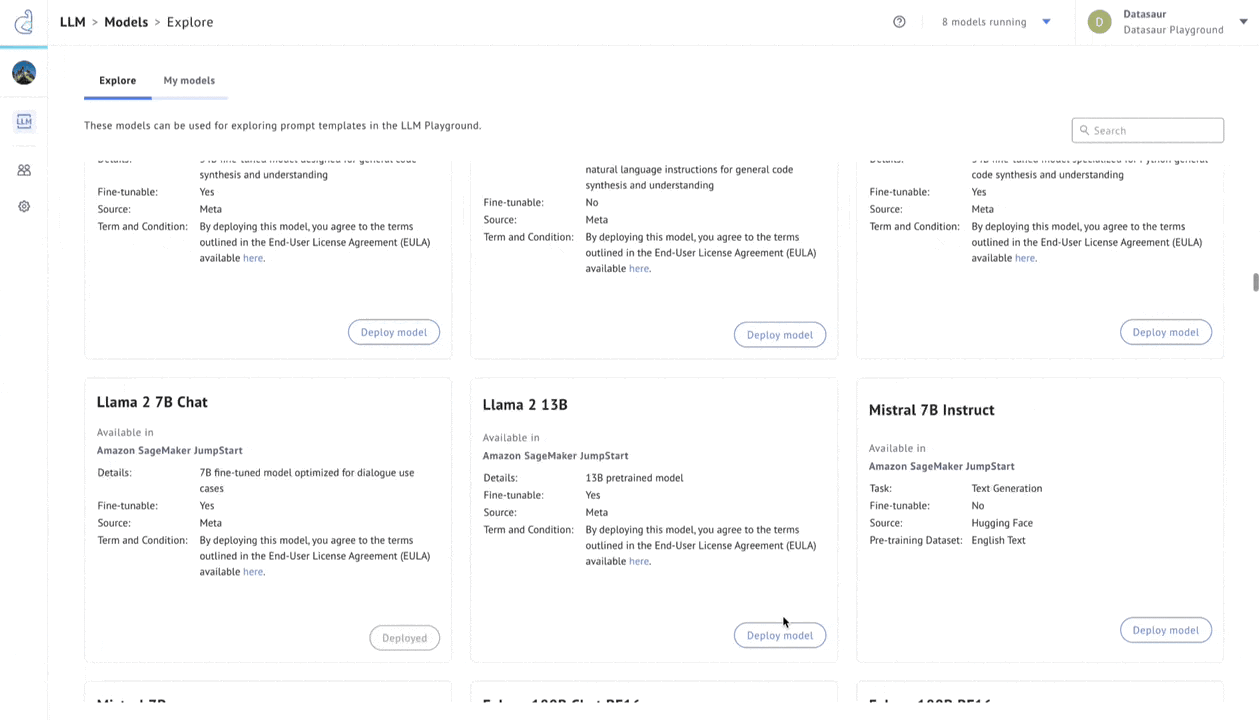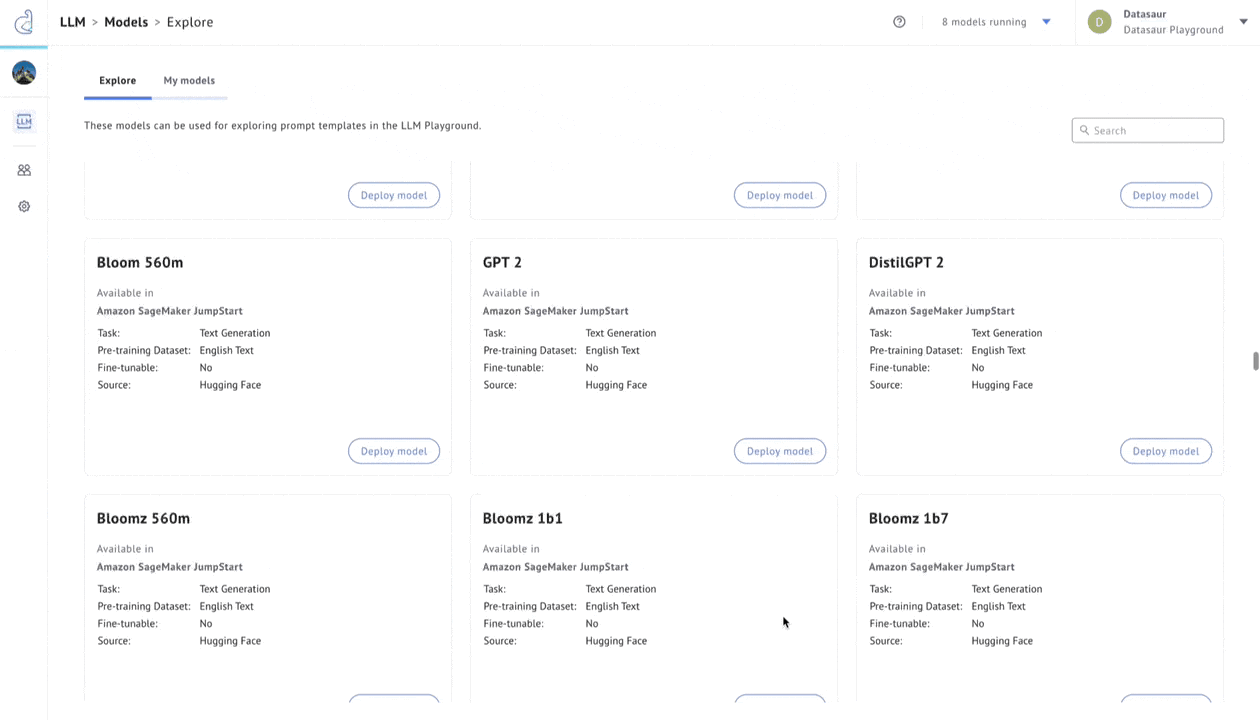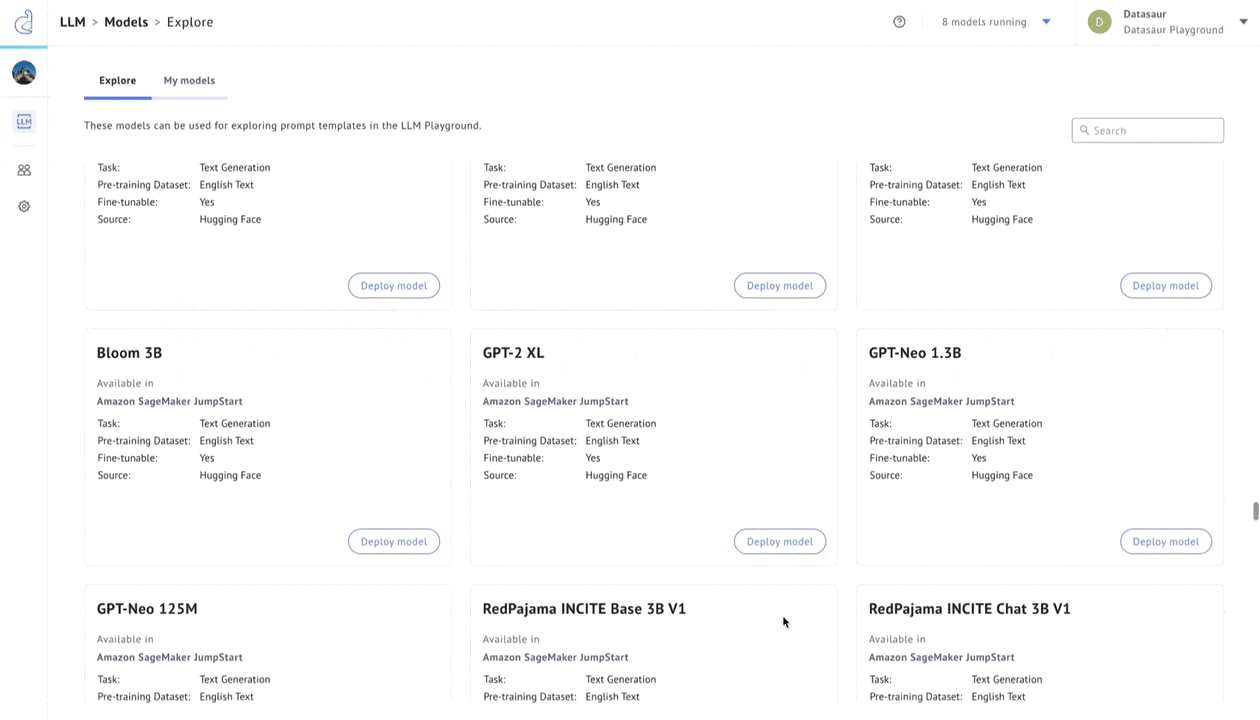
Figure 3 – LLM Labs.
Datasaur offers a solution in LLM Labs to evaluate accuracy, cost savings, and performance. LLM Labs integrates with Amazon SageMaker JumpStart to offer 80+ of the most popular models, allowing users to configure any of these models and connect them to proprietary datasets via retrieval augmented generation (RAG).
Once deployed, these models can be connected to Datasaur’s NLP Platform to automatically apply labels. Model flexibility allows using, for example, Dolly 7b for some tasks while reserving Llama 2 70b for more complex operations. Cost indicators help with pricing transparency and estimating cost-performance tradeoffs.
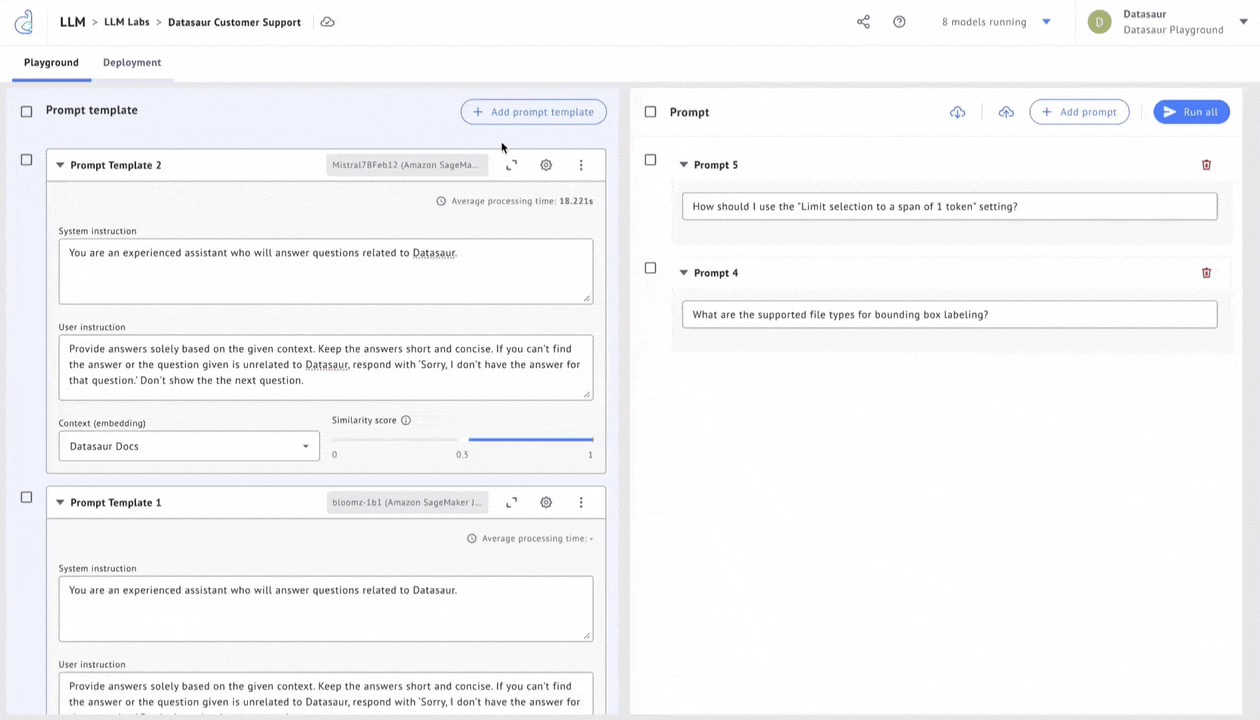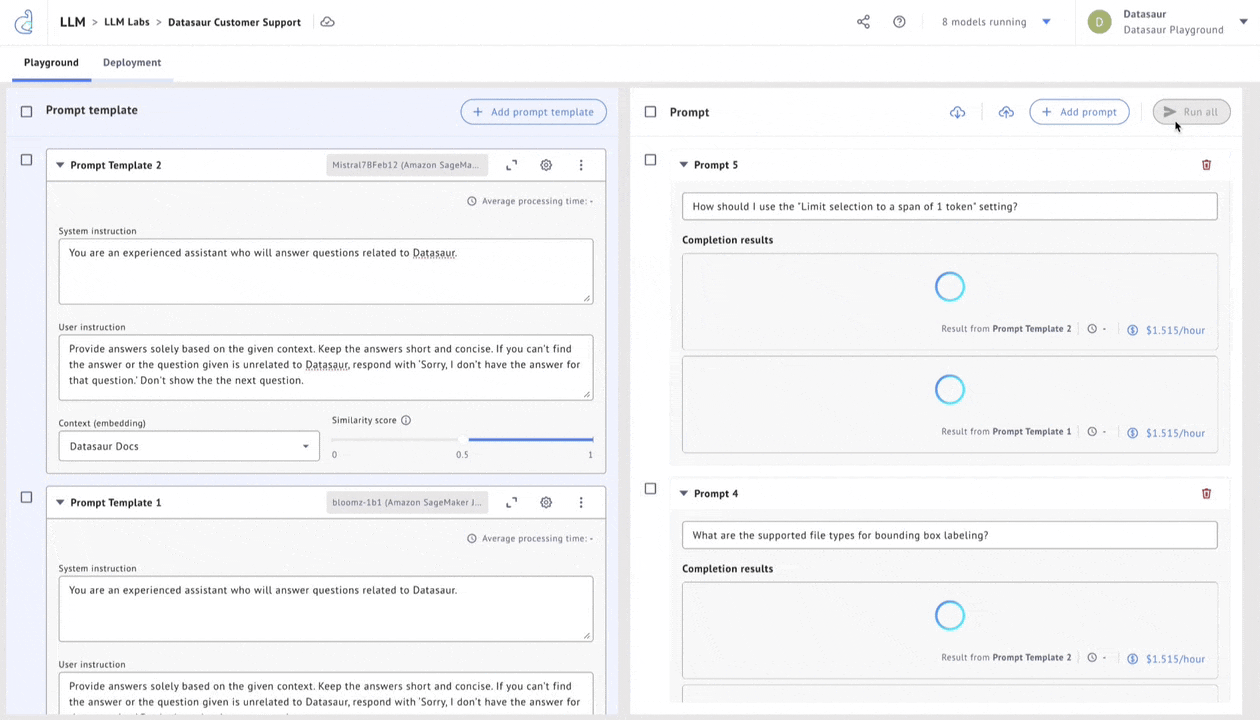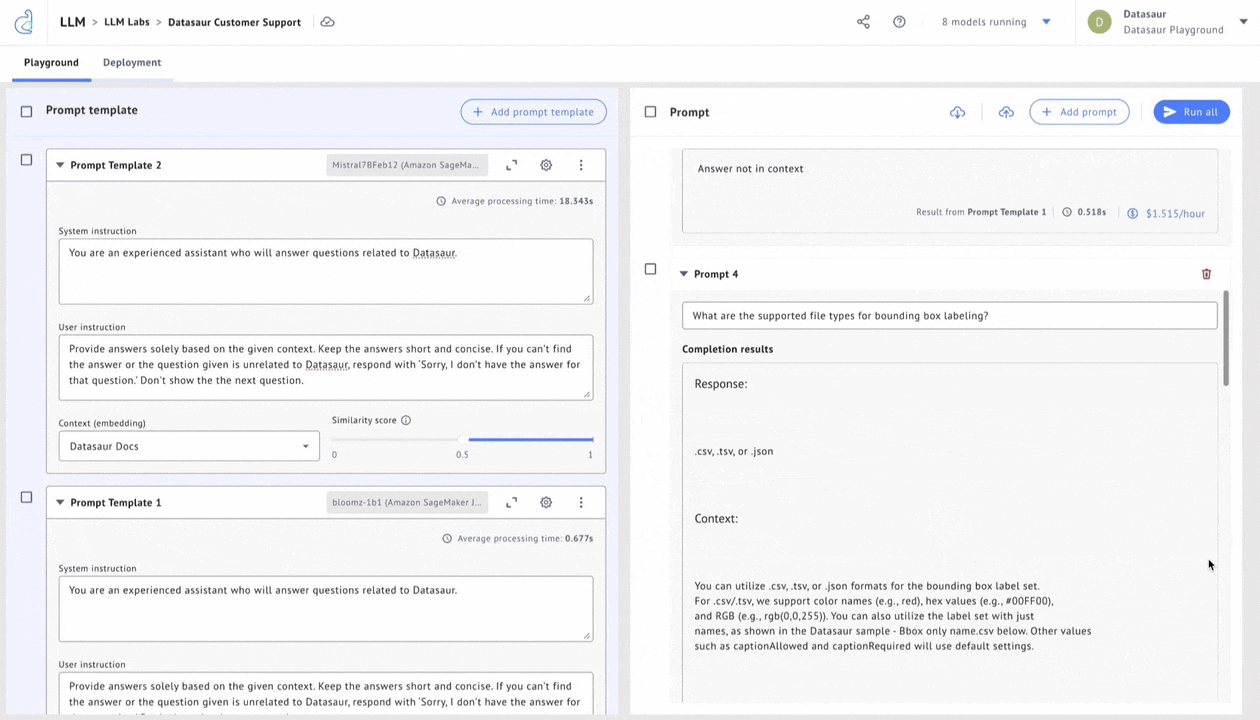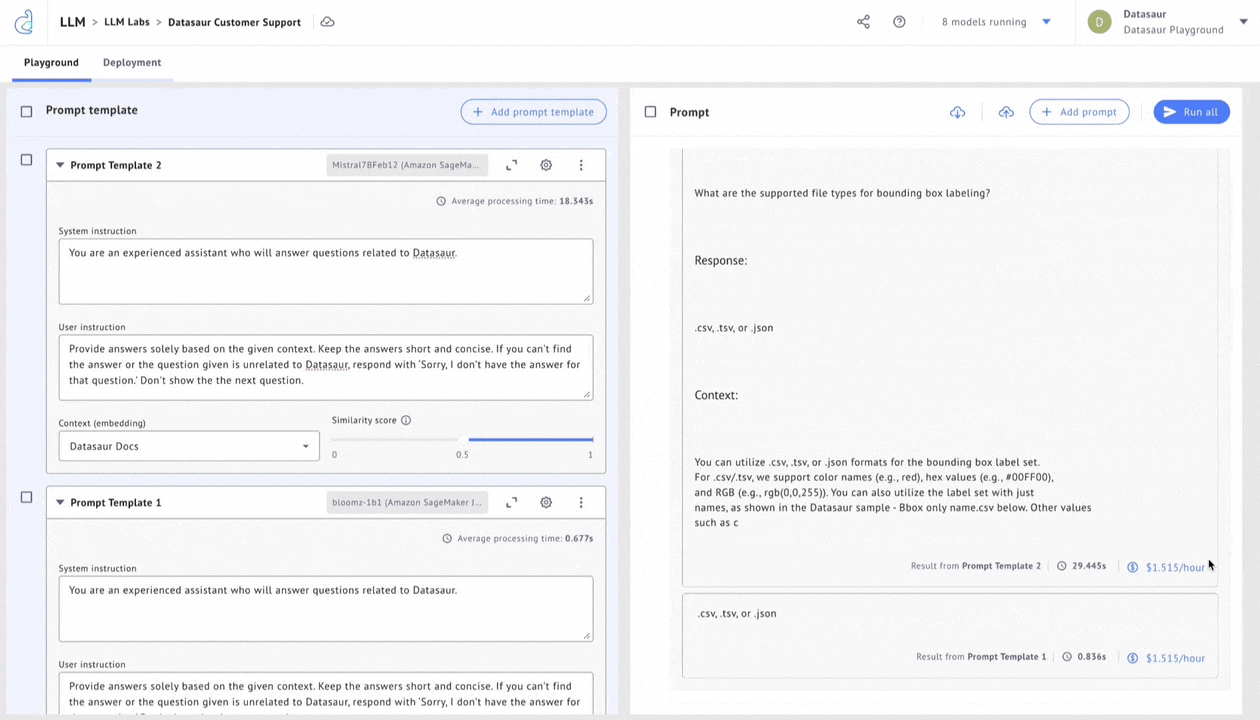
Figure 4 – Choose a model by evaluating responses, cost, and performance.
Combine Generative AI with Traditional NLP Methods
One can take this integration one step further in setting up an LLM distillation workflow. Assume we are working with a 250,000-row dataset. Users can call LLM Labs to label the first 10,000 rows. A human-in-the-loop can review and validate these answers in the NLP Platform, and then use SageMaker’s AutoML capabilities to train a preliminary model with this initial 10,000-row dataset.
The user can then create another 25,000-row dataset but, instead of calling an expensive LLM they can apply labels using the SageMaker model a tenth the cost and 10x the speed. As users continue iterating through the 250,000-row dataset, they can reach a model that takes the LLM’s initial intelligent predictions and distill the understanding down to a smaller, significantly more efficient model that excels at precisely this task.
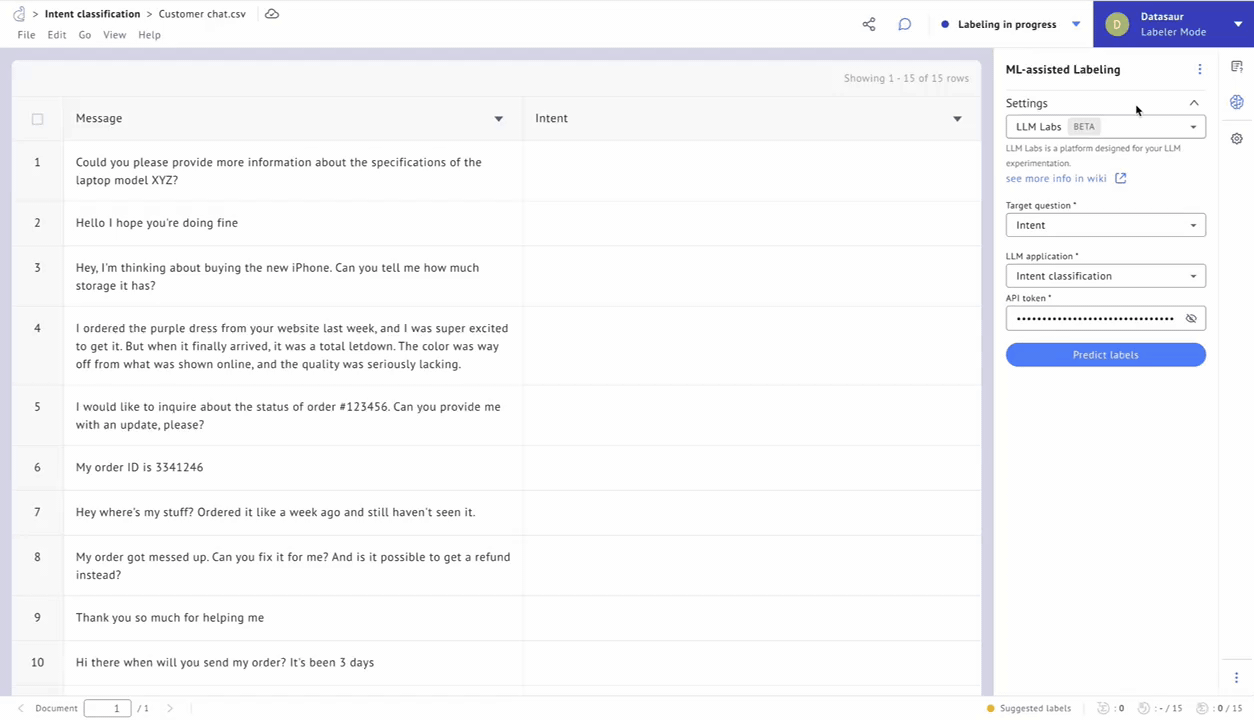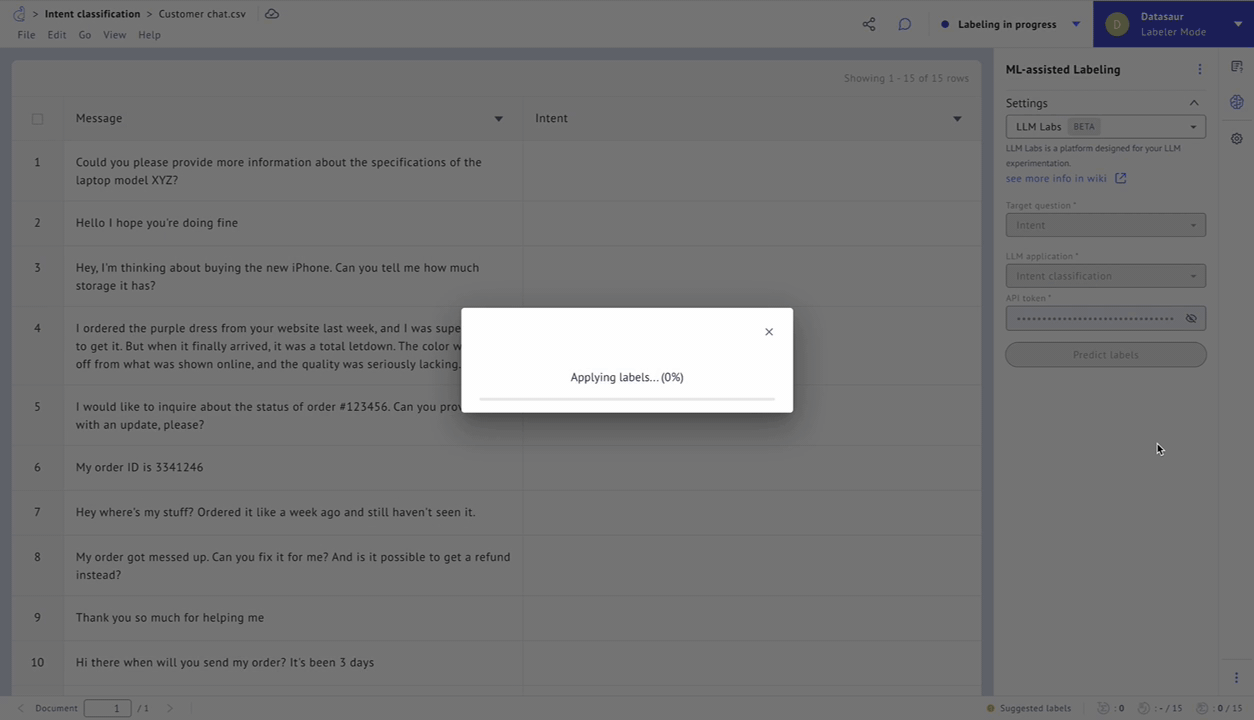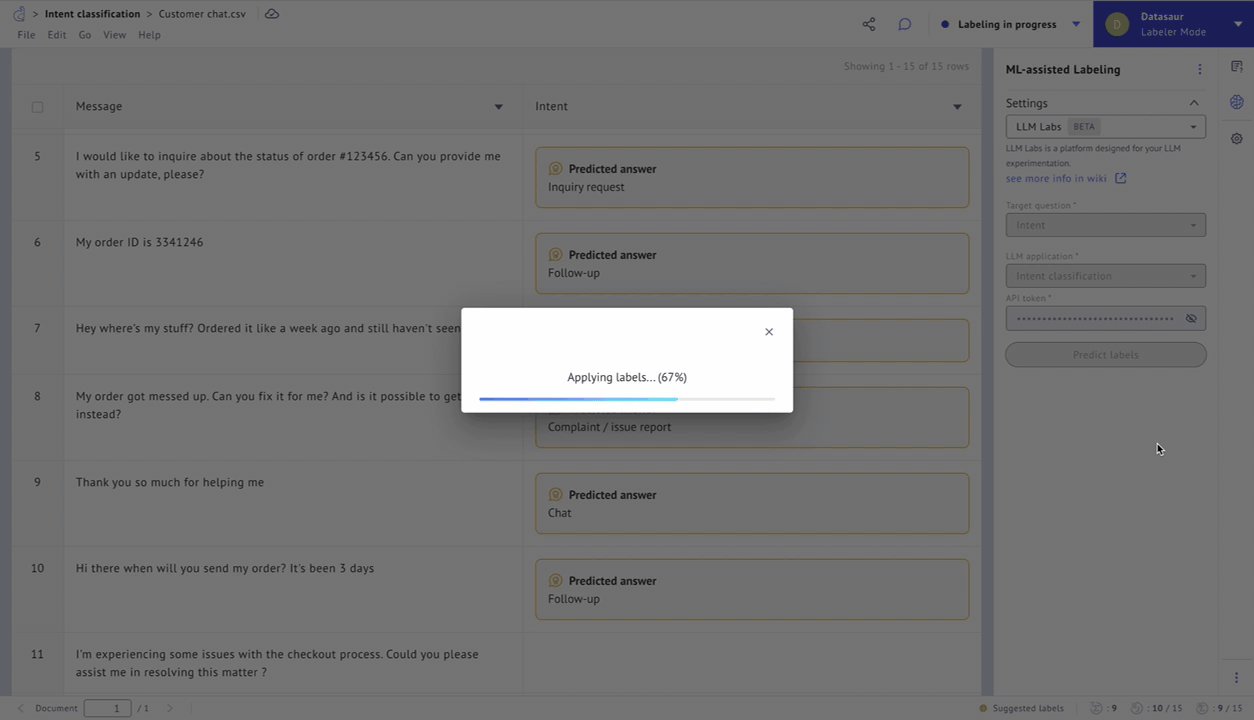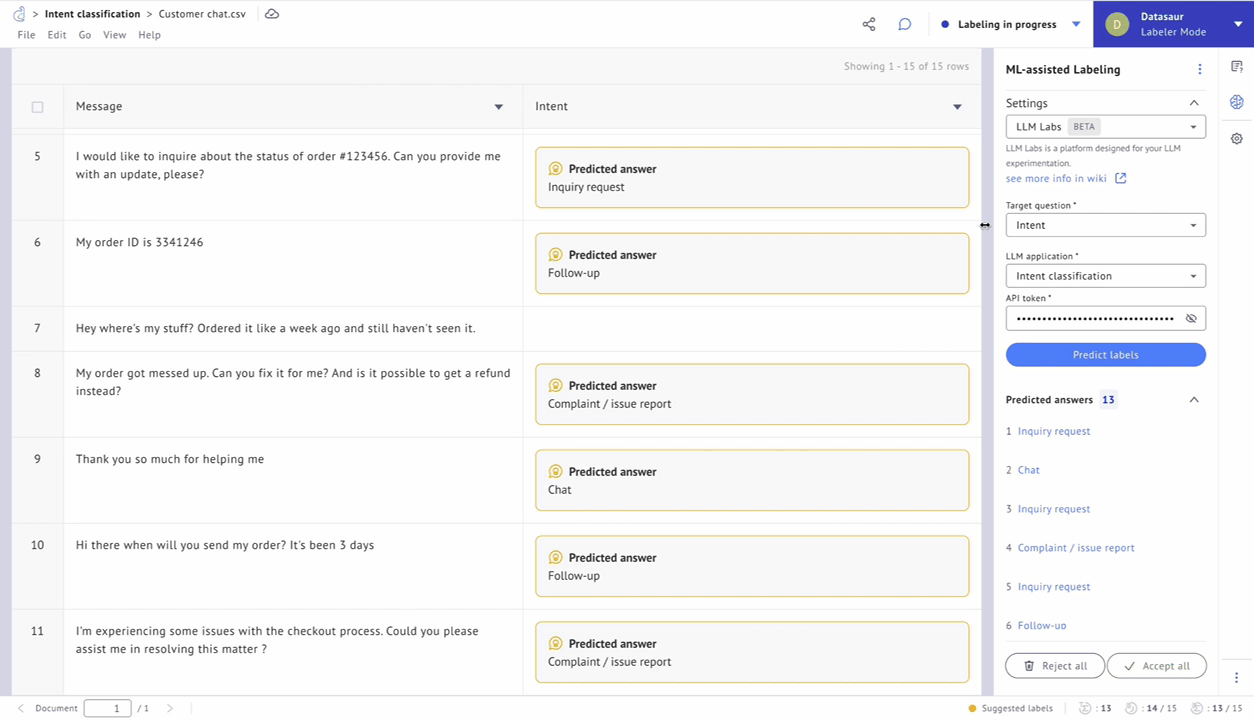
Figure 5 – Predict labels using LLM Labs.
With increasing interest in NLP operations and scaling models to production, LLM distillation will become a key tool in every data science team’s belt.
Note that teams should consult their attorneys about the LLM’s End-User License Agreement (EULA) when training models based on LLM-generated outputs.
Conclusion
In this post, you saw the current trends, challenges, and how Datasaur has collaborated with AWS to address these challenges through the NLP Platform and LLM Labs solutions. You also saw an example of how the two solutions can be combined to use as an end-to-end data labeling solution.
.
.
Datasaur – AWS Partner Spotlight
Datasaur is an AWS Partner that offers end-to-end data labeling NLP and large language model (LLM) solutions on AWS.
Contact Datasaur | Partner Overview | AWS Marketplace



