How LeadSquared accelerated chatbot deployments with generative AI using Amazon Bedrock and Amazon Aurora PostgreSQL

LeadSquared is a new-age software as a service (SaaS) customer relationship management (CRM) platform that provides end-to-end sales, marketing, and onboarding solutions. Tailored for sectors like BFSI (banking, financial services, and insurance), healthcare, education, real estate, and more, LeadSquared provides a personalized approach for businesses of every scale. LeadSquared Service CRM goes beyond basic ticketing, offering centralized support through their Converse omnichannel communications platform, personalized interactions, artificial intelligence (AI)-driven ticket routing, and data-driven insights.
Within Service CRM, the Converse multi-channel messaging platform facilitates real-time conversations with leads and customers across WhatsApp, SMS, and chatbots. Users of the Converse platform expressed a need for expedited onboarding of chatbot functionality and more relevant responses based on their business data. Accelerating this onboarding process presented several challenges, including the time-consuming tasks of training the bot to respond to frequently asked questions and their variations, comprehending the customer domain, identifying high-volume yet low-value queries, and managing dialogue effectively. Lack of proper training data could lead to chatbots misinterpreting user intent and struggling to address unexpected questions. Additionally, dialogue management posed another challenge, requiring careful consideration of user context in responses.
LeadSquared decided on an approach of using a large language model (LLM) augmented with customer-specific data to improve the quality of the chatbot responses and streamline the onboarding process. LeadSquared built their solution using a combination of an Amazon Aurora PostgreSQL-Compatible Edition database, the pgvector extension of PostgreSQL, the supported LLMs in Amazon Bedrock, and Retrieval Augmented Generation (RAG). LeadSquared already uses Amazon Aurora to store a variety of essential data for its operations. As a result, it was logical to use Aurora for storing vector embeddings and perform hybrid searches as required. Amazon Bedrock offers foundation models (FMs) from Amazon and leading AI startups through an API, allowing LeadSquared to experiment with and choose the best models to suit their needs. The API-based pricing model of Amazon Bedrock offered LeadSquared an affordable scaling solution without the burden of managing the infrastructure for hosting LLMs independently.
The solution retrieves data from outside the language model such as videos, help documents, case history, existing FAQs, and their knowledge base. It enhances prompts that improve the LLM user responses by incorporating the pertinent retrieved data in context. As a result, LeadSquared is now able to offer easier chatbot setup, provide a more personalized experience based on end customer-specific data, better understand user intent, improve dialogue management, and automate repetitive tasks.
Prashant Singh, COO and Cofounder at LeadSquared, says,“The integration of RAG capabilities using Amazon Aurora PostgreSQL with the pgvector extension and LLMs available in Amazon Bedrock has empowered our chatbots to deliver natural language responses to out-of-domain inquiries, enhanced dialogue management, and reduced our manual efforts. Consequently, we have observed a 20% improvement in customer onboarding times”.
This post showcases how to build a chatbot similar to LeadSquare’s chatbot. We demonstrate how to use domain-specific knowledge from multiple document formats, including PDFs, videos, text files, and presentations, to produce more effective textual prompts for the underlying generative AI models. Additionally, we show how to code such a chatbot using the pgvector extension and LLMs available in Amazon Bedrock. The built-in PostgreSQL pgvector extension in Aurora facilitates the storage of vector embeddings, empowering the system with semantic search capabilities. Simultaneously, the Amazon Bedrock APIs play a dual role: generating vector embeddings, and furnishing pertinent responses for user queries with domain-specific knowledge.
Solution overview
Suppose that your company deploys a Q&A bot on your website. When a customer reaches out with a specific query or issue, the bot retrieves relevant information from your customer database, product manuals, FAQs, and previous support interactions. Your chatbot application uses this data to build a detailed prompt that includes the relevant context. Then, an LLM can use this prompt to generate a coherent and contextually appropriate response that incorporates your business data. This two-step mechanism for producing better results rather than feeding the user’s prompt directly to the LLM is known as Retrieval Augmented Generation (RAG).
The well-known LLMs are trained on general bodies of knowledge, making them less effective for domain-specific tasks. For specialized knowledge-intensive tasks, you can build a language model-based system that accesses knowledge sources beyond the original training data for the LLM. This approach enables more factual consistency, improves the reliability of the generated responses, and helps reduce the problem of hallucination.
Let’s look at the RAG mechanism used in this post in more detail.
Retrieval
RAG first retrieves relevant text from a knowledge base, like Aurora, using similarity search. The text produced in this step contains information related to the user’s query, although not necessarily the exact answer. For example, this first step might retrieve the most relevant FAQ entries, documentation sections, or previous support cases based on the customer’s question. The external data can come from sources such as document repositories, databases, or APIs.
This post uses the pgvector extension to do the initial retrieval step for the RAG technique. pgvector is an open source extension for PostgreSQL that adds the ability to efficiently store and rapidly search machine learning (ML)-generated vector embeddings representing textual data. It’s designed to work with other PostgreSQL features, including indexing and querying. In an application such as a Q&A bot, you might transform the documents from your knowledge base and frequently asked questions and store them as vectors.
In this post, knowledge resources encompassing various formats like PDFs, texts, videos are transformed into vectorized representations using the Amazon Titan Text Embeddings model. These embeddings are stored within Amazon Aurora PostgreSQL, facilitated by the pgvector extension for subsequent stages.
Generation
After the relevant text is retrieved, RAG uses an LLM to generate a coherent and contextually relevant response. The prompt for the LLM includes the retrieved information and the user’s question. The LLM generates human-like text that’s tailored to the combination of general knowledge from the FM and the domain-specific information retrieved from your knowledge base.
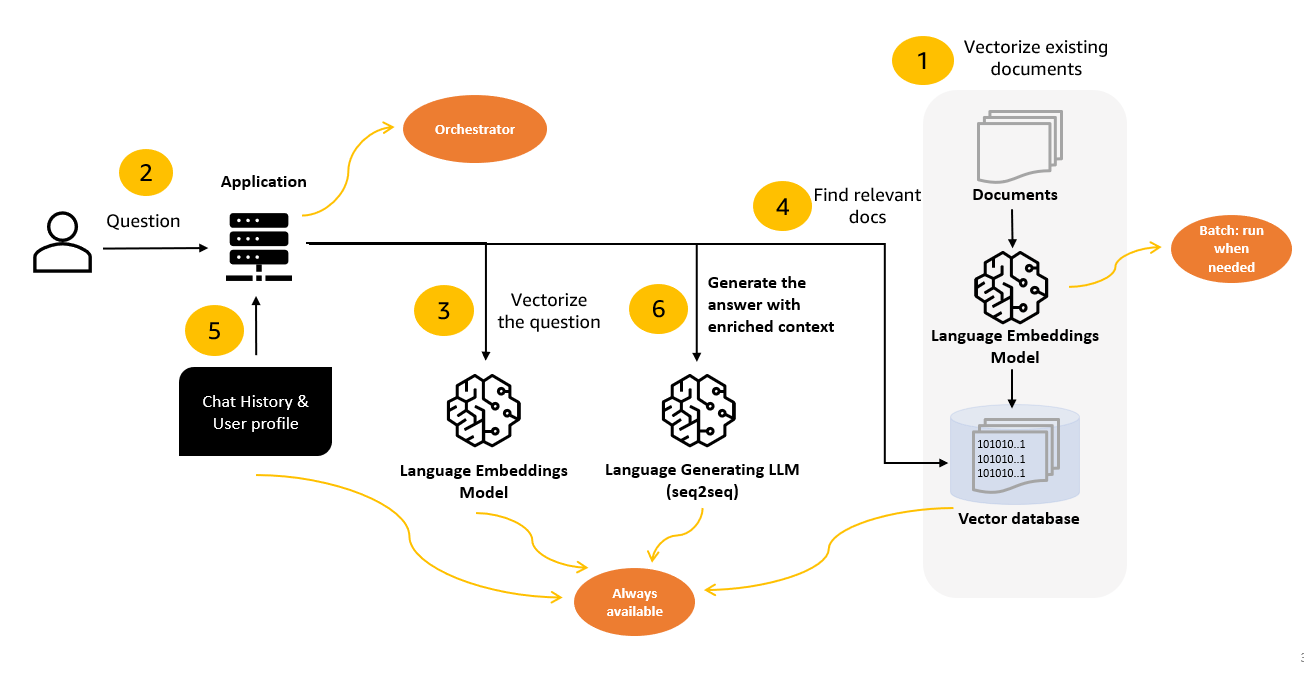
The following diagram illustrates the process.
The steps are as follows:
- The first step in the process involves transforming documents and user queries into a standardized format that enables effective search and comparison. This transformation process, known as embedding, converts textual data into semantical equivalents numerical arrays (vectors).
- Next, the user submits a query to the application. This orchestrates the entire workflow.
- The application generates an embedding for the user query. The same embeddings model used in Step 1 should be used to generate embeddings of the user query in Step 3.
- The embedding is then compared to the embeddings representing documents from the knowledge base. This comparison identifies documents that are the most relevant to the query. The application extracts snippets from these documents and appends them to the original query.
- This augmented prompt is enriched with relevant context from the knowledge base, chat history, and user profile.
- The augmented prompt is forwarded to the LLM to generate the response that the user sees. The advantages of using Amazon Bedrock are that the LLM endpoints are always available.
You can keep the system up to date by updating the knowledge base and its corresponding embeddings as needed to provide accurate responses based on the updated data.
Solution architecture
The following diagram shows the technical components involved in the sample chatbot application and how data flows through the system.
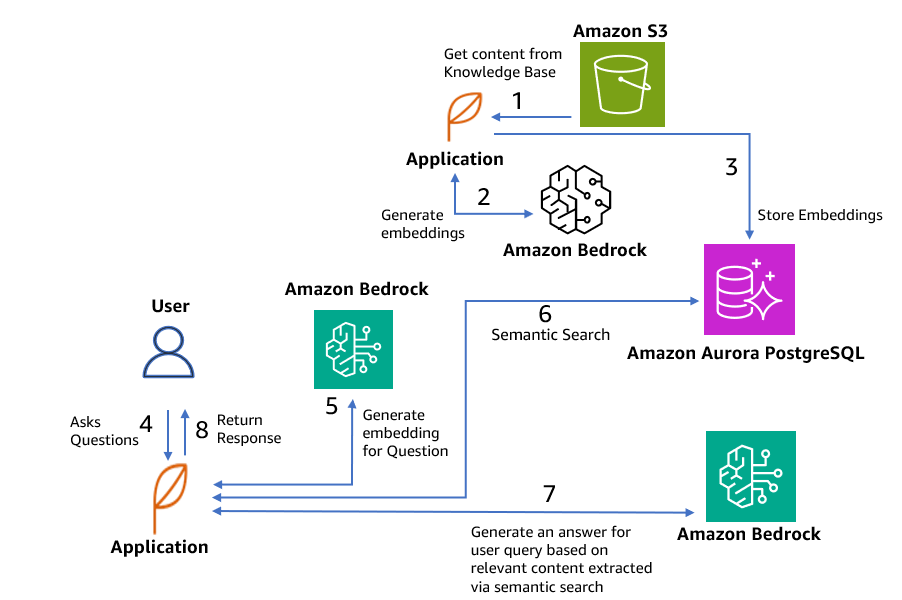
The workflow steps are as follows:
- You start from an already existing repository of knowledge resources. The formats can include PDFs, text documents, videos, and more.
- With the Amazon Titan Text Embeddings G1 model from Amazon Bedrock, these resources are transformed into vector representations, maintaining their semantic for advanced processing.
- The generated vector embeddings are stored within an Aurora PostgreSQL database using the pgvector capabilities for efficient vector storage and retrieval.
- A user initiates the process by posing a question, for instance, “How can AWS support vector databases?”
- The user’s question is translated (with the same model in Step 2) into its vector embeddings, facilitating subsequent computational comparisons with the embeddings generated from the knowledge base. A semantic search operation is run on the Aurora PostgreSQL database, employing the vectorized representations to identify chunks of knowledge resources with relevant information.
- The extracted answers from the search are fed into the Amazon Bedrock model along with the user query. You can use any of the LLMs available in Amazon Bedrock. For demonstration purposes, we use the Anthropic Claude v2.1 model. You can also deploy your own models in Amazon SageMaker JumpStart and use its endpoint.
- Using the enhanced context derived from the semantic search, the Claude v2.1 model generates a comprehensive response, which is subsequently delivered back to the user.
For pricing details for Amazon Bedrock, refer to Amazon Bedrock Pricing.
Prerequisites
Complete the following prerequisite steps before you deploy the application:
- Set up an Aurora PostgreSQL cluster in a private subnet with pgvector support. The pgvector extension version 0.5.0 is available on Amazon Aurora PostgreSQL 15.4, 14.9, 13.12, 12.16, and higher in all AWS Regions. pgvector v0.5.0 supports Hierarchical Navigable Small World (HNSW) indexing, parallelization of ivfflat index builds, and improved performance of distance calculator functions. Refer to Extension versions for Amazon Aurora PostgreSQL for details about the pgvector versions supported.
- Run the following command in the database to enable the pgvector extension:
- Set up an Amazon Elastic Compute Cloud (Amazon EC2) instance in a public subnet. This instance acts as a client to deploy the application and to access the database. For instructions, refer to Tutorial: Get started with Amazon EC2 Linux instances. The EC2 instance must have a public IP and a permissive security group for the port to be used by the Streamlit application (default port: 8501).
- Create an AWS Secrets Manager database secret for the application to access Aurora. For instructions, see Create an AWS Secrets Manager database secret.
- To start using FMs in Amazon Bedrock, request access to the models you intend to use. We use the Claude v2.1 model for the application.
- The EC2 instance requires access to the Aurora database cluster, Secrets Manager, and Amazon Bedrock. For the steps to create an AWS Identity and Access Management (IAM) role and attach specific policies granting access to those resources, refer to Creating a role to delegate permissions to an AWS service.
- (Optional) Depending on the document formats you plan to use as input sources, set up the following prerequisites:
- PPT or .docx as a source – Install LibreOffice in your EC2 machine, which will be used to access presentations or .docx file types.
- Amazon S3 as a source – Create an Amazon Simple Storage Service (Amazon S3) bucket and attach a policy to the role you created earlier to allow access to this bucket. For instructions, refer to Create your first S3 bucket. You can upload the following example document to the S3 bucket under the documentEmbeddings/ prefix to use while testing the application.
Code walkthrough
The application code is written in Python 3.10 using LangChain. LangChain is a framework for developing applications powered by language models. LangChain helps you connect a language model to other sources of data, and also to interact with its environment.
The following is the code walkthrough of the main functions in the application.
Load the source data
The initial step is to identify the source. Depending on the specific source, you call the appropriate LangChain document loader function, as shown in the following code. To learn more about the document loader functions, refer to Document loaders.
Chunk the data
After you’ve loaded the documents, you can transform them to better suit your application. For example, you might split a long document into smaller chunks that can fit into your model’s context window. LangChain has several built-in document transformers that make it straightforward to split, combine, filter, and otherwise manipulate documents. The document transform function varies based on the document type. For more information about the different transformation mechanisms, refer to Text Splitters. The following example uses a text splitter to split a document into smaller chunks:
Generate embeddings and store them in Amazon Aurora PostgreSQL
In the next step, you create and store the embeddings generated by the Amazon Titan Text Embeddings G1 model directly into the Aurora PostgreSQL database, as shown in the following code. For more information on the LangChain Amazon Bedrock functions, refer to the LangChain documentation for Amazon Bedrock.
Create a conversation chain
Based on the user input and the chat history that is retrieved from the provided buffer memory, the relevant documents are retrieved from the Aurora PostgreSQL vector store. Then the code passes those documents and sends the question to the Claude v2.1 model via Amazon Bedrock to return a response. See the following code:
Deploy the application
The following GitHub folder provides a Streamlit application, which you can use to test the application. Complete the following steps to deploy the app:
- Download the folder in your frontend EC2 instance.
- Replace the database secret in the code so that your application can fetch the database endpoint and credentials for your Aurora database.
- Make sure that Python version >= 3.10 and pip3 >=20.0.0 is installed on Amazon EC2.
- Navigate to the folder and install the requirements by running the following command:
5.To start the application, run the following command:
6. Navigate to the external URL provided as the output of the preceding command.

The following screenshot shows what the landing page looks like when you open it in the UI.
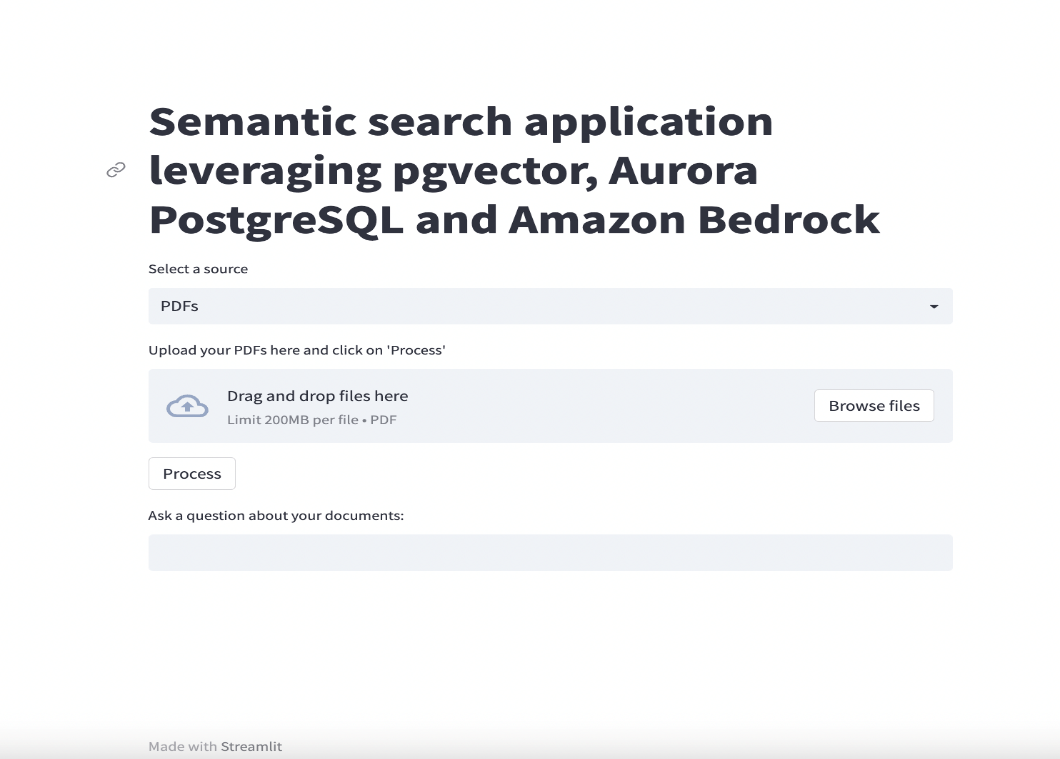
In the following sections, we explore some examples of using different file types as a source in our application. All the example files are available in the GitHub repository.
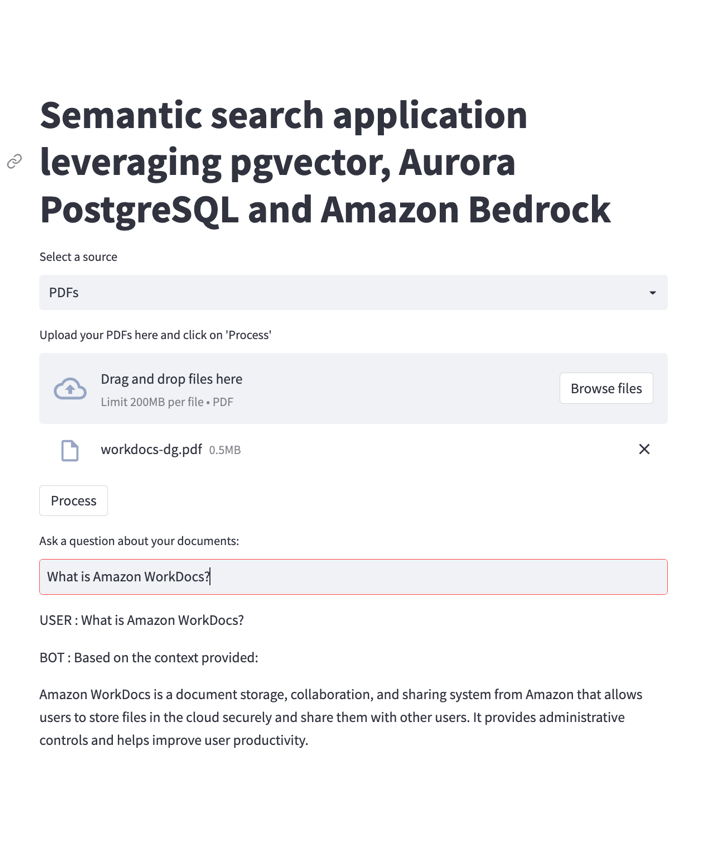
PDF as a source
In this example, we use the following PDF document, which is the user guide for Amazon WorkDocs and provides extra context for the chatbot. The first question refers to Amazon WorkDocs.
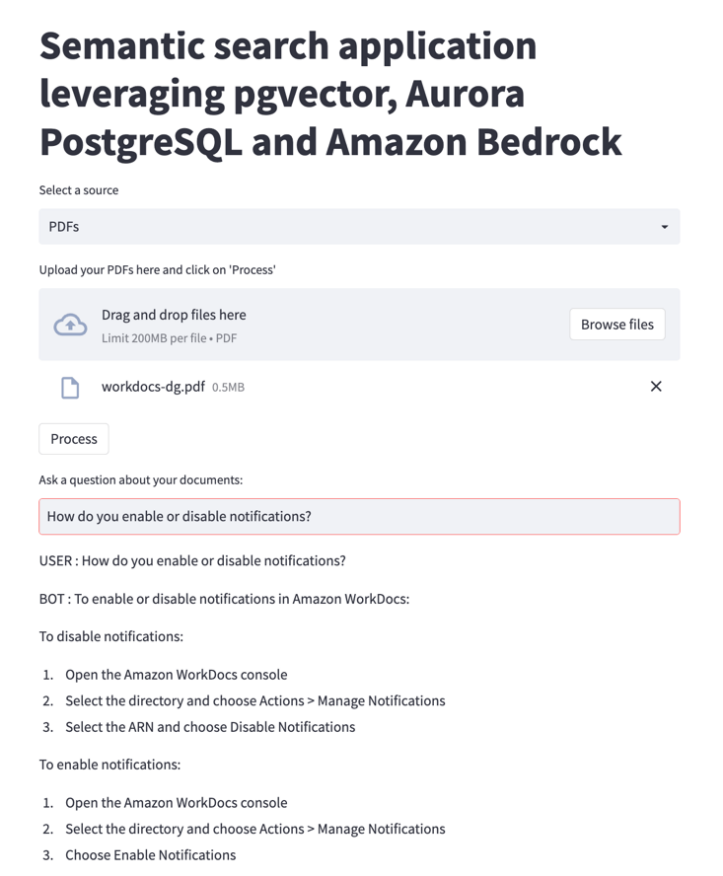
When a subsequent question asks about notifications, the chatbot responds about notifications specifically in WorkDocs as the conversation (chat) history data is also provided as input to LLM.
Amazon S3 as a source
In this example, the source document (which you uploaded to Amazon S3 as a prerequisite) provides extra context with answers to the frequently asked questions about Aurora. The chatbot builds the answer by synthesizing text from the most relevant FAQ entries instead of repeating the original text verbatim.

YouTube videos as a source
For this example, suppose that your company has a set of videos related to training, product demonstrations, and so on. You can have the text from the video transcriptions already transformed into vector embeddings and stored in your database. When a user asks a question about a product, the chatbot can locate related videos and build the answers using the context from the video transcriptions.

PPT as a source
For this example, suppose that your company has a set of marketing or instructional materials in PowerPoint format. There might be details in the slide decks that are relevant to the user’s question, but it wouldn’t be helpful to ask the user to download the entire slide deck, or to display the terse bullet points verbatim. The chatbot can combine details from the presentation text with general information from an LLM, and display a natural-sounding conversational response. For example, the sample slide deck doesn’t contain the word “versus” or its abbreviation “vs.” The LLM can interpret that the user question is asking for a compare-and-contrast response and build an answer using details from the PowerPoint document.
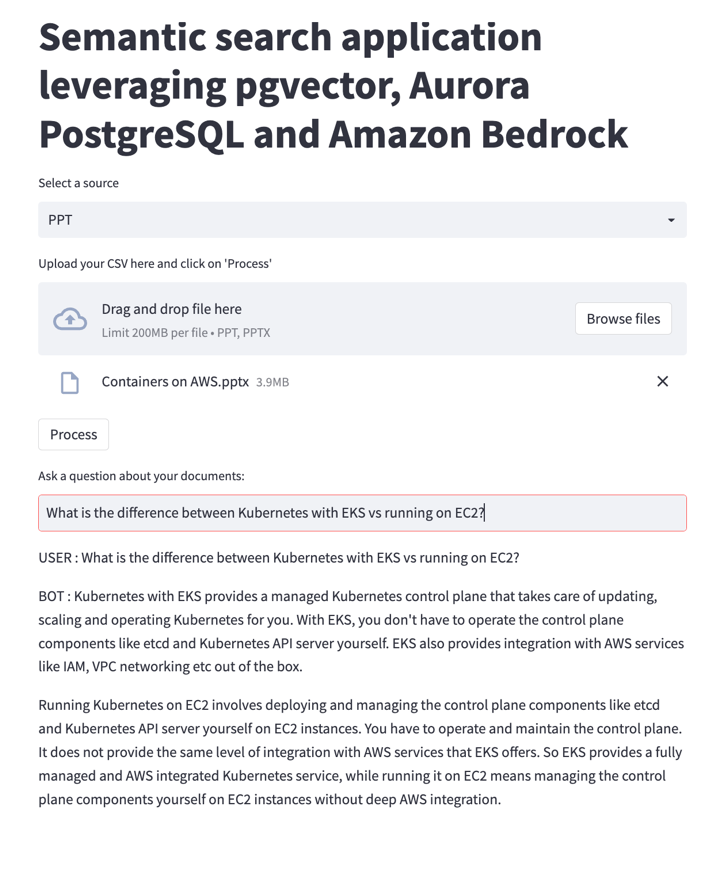
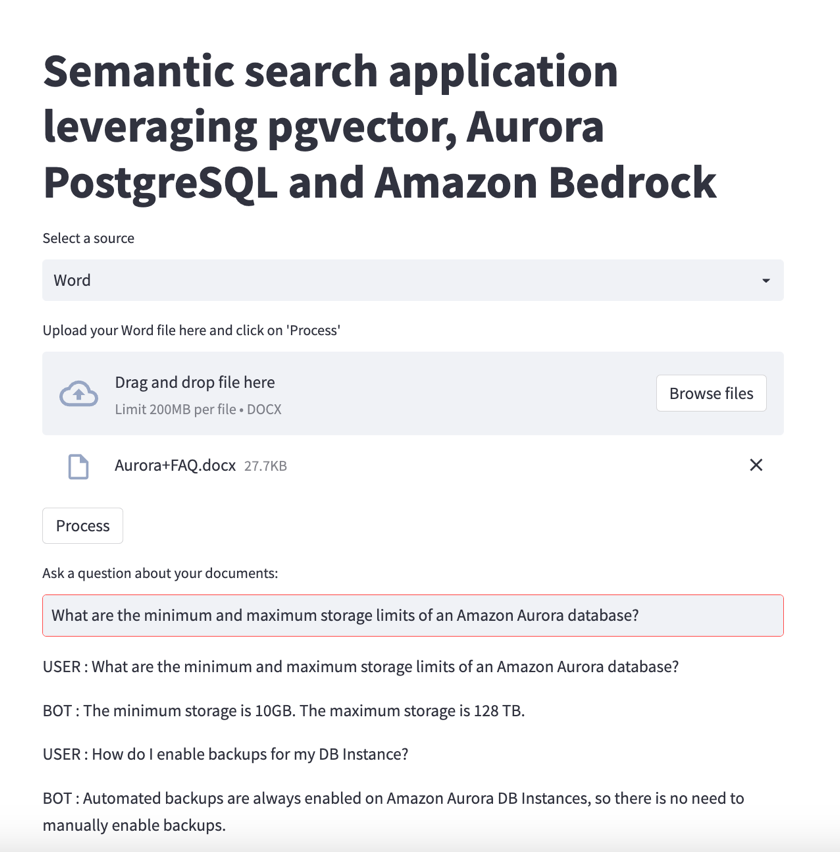
Word document as a source
For this example, suppose that your company has supplemental documentation written in Microsoft Word format, even though the majority of the user-facing information uses a different document format. You can make the information from the Word documents available to answer customer questions without going through a complicated document conversion process, and without requiring users to download an entire manual or instruction sheet and search through it for the answer.
Clean up
When you’re done using the application, complete the following steps to clean up your resources:
- Delete the Aurora database created as part of the prerequisites.
- Stop the EC2 instance that was hosting the Streamlit application.
- Delete the S3 bucket and the file you uploaded.
- Delete the IAM role, security group configuration, Secrets Manager secret, and any other resources created as part of this post.
Conclusion
Generative AI technologies find frequent application in chatbots designed for conversational interactions with customers, particularly for companies providing CRM platforms or service desk software. These chatbots play a crucial role in enhancing a company’s support experience by providing swift and helpful assistance, streamlining CRM processes, and efficiently addressing service desk inquiries. LeadSquared was able to add generative AI-powered chatbots to the Converse omnichannel communications platform and use RAG to personalize each chatbot for specific customer requirements using their training data. The end result is reduced cost for customer onboarding, less manual effort, and better chatbot responses for their customers.
In this post, we showed you how the pgvector extension in Amazon Aurora PostgreSQL and LLMs available through Amazon Bedrock offer an innovative opportunity to create intelligent and efficient natural language Q&A bots. By integrating these technologies, businesses can build Q&A bots that not only retrieve information from vast datasets using vector-based retrieval methods (RAG), but also generate contextually relevant and human-like responses. As businesses continue to explore and integrate these technologies, the landscape of customer interactions is bound to be transformed, ushering in a more intuitive, responsive, and user-friendly era of customer support and engagement.
About the Authors
 Prakash Jothiramalingam is a passionate proponent of AI-driven business value, Prakash spearheads engineering for LeadSquared’s Service CRM, Converse, and ACE product lines as their Vice President of Engineering.
Prakash Jothiramalingam is a passionate proponent of AI-driven business value, Prakash spearheads engineering for LeadSquared’s Service CRM, Converse, and ACE product lines as their Vice President of Engineering.
 David John Chakram is a Principal Solutions Architect at AWS. He specializes in building data platforms and architecting seamless data ecosystems. With a profound passion for databases, data analytics, and machine learning, he excels at transforming complex data challenges into innovative solutions and driving businesses forward with data-driven insights.
David John Chakram is a Principal Solutions Architect at AWS. He specializes in building data platforms and architecting seamless data ecosystems. With a profound passion for databases, data analytics, and machine learning, he excels at transforming complex data challenges into innovative solutions and driving businesses forward with data-driven insights.
 Steve Dille is a Senior Product Manager for Amazon Aurora, and leads all generative AI strategy and product initiatives with Aurora databases for AWS. Previous to this role, Steve founded the performance and benchmark team for Aurora and then built and launched the Amazon RDS Data API for Amazon Aurora Serverless v2. He has been with AWS for 4 years. Prior to this, he served as a software developer at NCR, product manager at HP, and Data Warehousing Director at Sybase (SAP). He has over 20 years of experience as VP of Product or CMO on the executive teams of companies, resulting in five successful company acquisitions and one IPO in the data management, analytics, and big data sectors. Steve earned a Master’s in Information and Data Science at UC Berkeley, an MBA from the University of Chicago Booth School of Business, and a BS in Computer Science/Math with distinction from the University of Pittsburgh.
Steve Dille is a Senior Product Manager for Amazon Aurora, and leads all generative AI strategy and product initiatives with Aurora databases for AWS. Previous to this role, Steve founded the performance and benchmark team for Aurora and then built and launched the Amazon RDS Data API for Amazon Aurora Serverless v2. He has been with AWS for 4 years. Prior to this, he served as a software developer at NCR, product manager at HP, and Data Warehousing Director at Sybase (SAP). He has over 20 years of experience as VP of Product or CMO on the executive teams of companies, resulting in five successful company acquisitions and one IPO in the data management, analytics, and big data sectors. Steve earned a Master’s in Information and Data Science at UC Berkeley, an MBA from the University of Chicago Booth School of Business, and a BS in Computer Science/Math with distinction from the University of Pittsburgh.
 Chirag Tyagi is a Senior Solutions Architect at Amazon Web Services with over a decade of experience in helping customers achieve their business objectives with a focus on databases and analytics. He is currently working with ISV customers on their cloud journey by helping them design, architect, and innovate highly scalable and resilient solutions on AWS.
Chirag Tyagi is a Senior Solutions Architect at Amazon Web Services with over a decade of experience in helping customers achieve their business objectives with a focus on databases and analytics. He is currently working with ISV customers on their cloud journey by helping them design, architect, and innovate highly scalable and resilient solutions on AWS.




{kind=link}