Microsoft Azure’s Russinovich sheds light on key generative AI threats

Generative AI-based threats operate over a huge landscape, and CISOs must look at it from a variety of perspectives, said Microsoft Azure CTO Mark Russinovich during Microsoft Build conference this week in Seattle.
“We take a multidisciplinary approach when it comes to AI security, and so should you,” Russinovich said of the rising issue confronting CISOs today.
That means examining AI threats from the AI apps and underlying model code to their various API requests, to the training data used by machine learning algorithms, to potential backdoors that could poison your models, inject malware into user prompts to steal your data, or take control over the AI systems themselves. Russinovich, originator of the popular Winternals utilities, laid these out in a generative AI threat map that shows the relationship among all these elements.
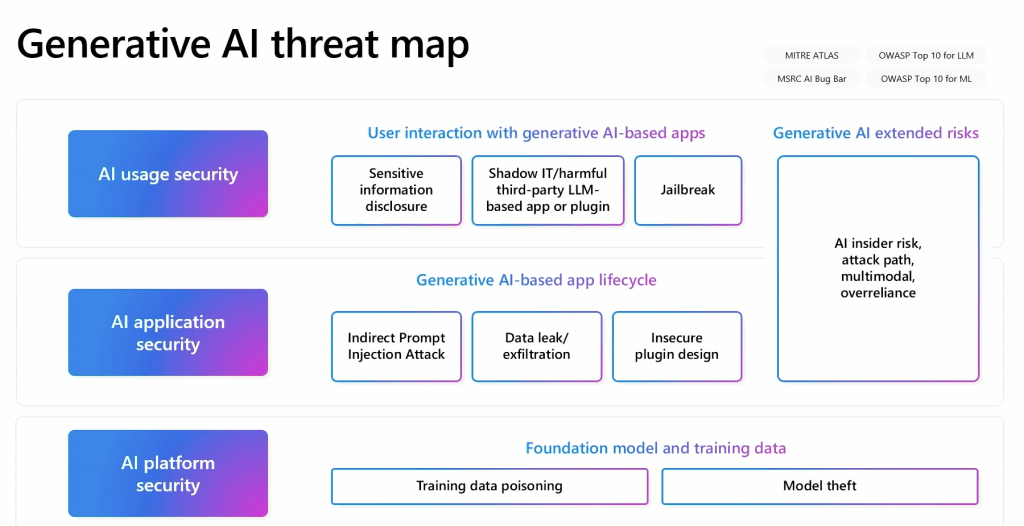
Russinovich showed this comprehensive threat map diagram, classifying the different types of potential exploits that generative AI could experience.
Microsoft
One key issue Russinovich shed light on was data poisoning. With this type of cyberattack, adversaries attempt to compromise an organization’s data set used to train their AI or machine learning models. Doing so can significantly corrupt the output.
“Someone could have access to your training data,” he said, and that could produce harmful responses, leak data, or insert backdoors for subsequent control and to introduce exploits down the road.
Russinovich used the example of planting poisoned data on a Wikipedia page that was known as a data source by the attacker. Once this data was scraped by the model, it didn’t matter if the Wikipedia editors caught the problem and deleted the bad data. “This makes it a lot harder to track down, because the poisoned data no longer exists.”
The Microsoft Azure CTO revealed that just by changing 1% of the data set — for example, using a backdoor — an attacker could cause a model to misclassify items or produce malware. Some of these data poisoning efforts are easily demonstrated, such as the effect of adding just a small amount of digital noise to a picture by appending data at the end of a JPEG file, which can cause models to misclassify images. He showed one example of a photograph of a panda that, when enough digital noise was added to the file, was classified as a monkey.
Not all backdoors are evil, Russinovich took pains to mention. They could be used to fingerprint a model which can be examined by software to ensure its authenticity and integrity. This could be oddball questions that are added to the code and unlikely to be asked by real users.
Probably the most infamous generative AI attacks are concerned with prompt injection techniques. These are “really insidious because someone can influence just more than the current dialog with a single user,” he said.
Russinovich demonstrated how this works, with a piece of hidden text that was injected into a dialog that could result in leaking private data, and what he calls a “cross prompt injection attack,” harking back to the processes used in creating web cross site scripting exploits. This means users, sessions, and content all need to be isolated from one another.
The top of the threat stack, according to Microsoft
The top of the threat stack and various user-related threats, according to Russinovich, includes disclosing sensitive data, using jailbreaking techniques to take control over AI models, and have third-party apps and model plug-ins forced into leaking data or getting around restrictions on offensive or inappropriate content.
One of these attacks he wrote about last month, calling it Crescendo. This attack can bypass various content safety filters and essentially turn the model on itself to generate malicious content through a series of carefully crafted prompts. He showed how ChatGPT could be used to divulge the ingredients of a Molotov Cocktail, even though its first response was to deny this information.
“AI LLMs have inherent security risks,” Russinovich said. “AI models are just like really smart but junior or naive employees. They have no real-world experience, they can be influenced, are persuadable and exploitable and can be convinced to do things that are against corporate policy. They are potentially loose cannons and need guardrails.”



