Streamline financial workflows with generative AI for email automation

Many companies across all industries still rely on laborious, error-prone, manual procedures to handle documents, especially those that are sent to them by email. Despite the availability of technology that can digitize and automate document workflows through intelligent automation, businesses still mostly rely on labor-intensive manual document processing. This represents a major opportunity for businesses to optimize this workflow, save time and money, and improve accuracy by modernizing antiquated manual document handling with intelligent document processing (IDP) on AWS. To extract key information from high volumes of documents from emails and various sources, companies need comprehensive automation capable of ingesting emails, file uploads, and system integrations for seamless processing and analysis. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
This post explains a generative artificial intelligence (AI) technique to extract insights from business emails and attachments. It examines how AI can optimize financial workflow processes by automatically summarizing documents, extracting data, and categorizing information from email attachments. This enables companies to serve more clients, direct employees to higher-value tasks, speed up processes, lower expenses, enhance data accuracy, and increase efficiency.
Challenges with manual data extraction
The majority of business sectors are currently having difficulties with manual document processing, and are reading emails and their attachments without the use of an automated system. These procedures cost money, take a long time, and are prone to mistakes. Manual procedures struggle to keep up with the number of documents. Finding relevant information that is necessary for business decisions is difficult. Therefore, there is a demand for shorter decision cycles and speedier document processing. The aim of this post is to help companies that process documents manually to speed up the delivery of data derived from those documents for use in business operations. By reducing the time and ongoing expenses associated with manual workflows, organizations can enhance productivity, responsiveness, and innovation through data analytics.
In the past, optical character recognition (OCR) worked well for flawless documents, but the performance of those old systems frequently did not meet customer needs when document quality was imperfect. Because mistakes are unavoidable in manual processes and double-checking every task can be expensive and time-consuming, variability is introduced into workflows. Companies with seasonal fluctuations in customer demand face challenges in staffing document processing to maintain quick customer service. The key is efficiently extracting the most vital data from extensive paperwork to enable prompt decisions. For example, a mortgage application may be over a thousand pages, but only a dozen or so data points critically impact the credit decision. The trick is pinpointing those key details among the flood of information in order to make timely loan approvals while still providing excellent service to applicant.
This post explores how generative AI can make working with business documents and email attachments more straightforward. Sample business considerations include financial industries that have seen an uptick in their user base. They need a back-office automation solution to extract details from emails and attachments, summarize the content to send downstream, classify the documents and content, and assign documents to human reviewers if required. At the same time, the solution must provide data security, such as PII and SOC compliance.
Solution overview
The accompanying code for this solution is available in the GitHub repo. The solution covers two steps to deploy generative AI for email automation:
- Data extraction from email attachments and classification using various stages of intelligent document processing (IDP). IDP is an industry term used for describing the mechanism for processing and extracting information out of structured, semi-structured, and unstructured documents using AI and machine learning (ML).
- Data summarization using large language models (LLMs).
The following figure provides a high-level overview of the pipeline steps you might go through while you develop your IDP solution.
The data capture stage is where documents are extracted from emails, compiled, and securely stored as input documents. There may occasionally be different sorts of documents and no automatic method for identifying and categorizing them. However, you can bypass the classification process and go directly to the next stage, which is accurately extracting information from your documents. In the enrichment stage, you can take the data and language from the documents and apply it in significant ways to enhance that data. A human-in-the-loop review is the last stage of the process, which enables you to request a human evaluation of data that has been extracted with a low degree of accuracy. Customers in highly regulated areas like financial services and healthcare are adding human evaluations to their pipelines in order to review the data points.
This solution offers the following key benefits:
- Elasticity – You have the flexibility to scale up or down with the needs of the business
- Innovation – You can automate document data extraction coming through email channels
- Cost savings – You can optimize costs related to manual effort and associated operational cost
Data extraction workflow
The following figure shows a high-level representation of the possible stages of streamlining financial workflows to build our solution.
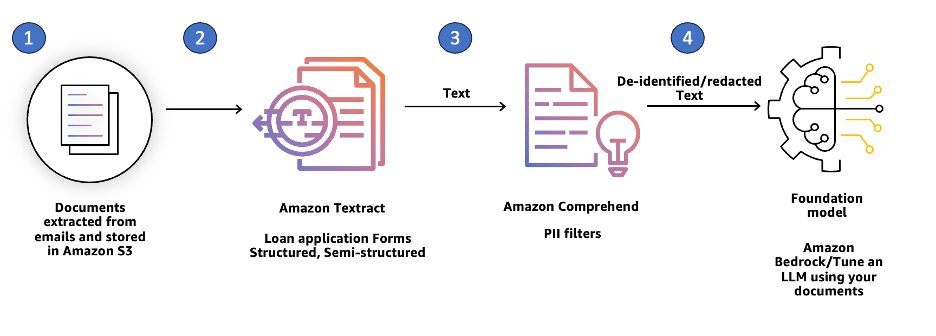
In the initial phase, the focus is to securely gather and compile data from documents, including email attachments. However, if you already have identifiable documents, you can bypass the classification process and proceed directly to the next phase. In the second step, you extract information accurately from your documents. In the third step, you can use extracted text and data to construct meaningful enhancements for these documents. The fourth and final step involves using foundation models (FMs) to standardize keys and values. This stage focuses on refining form data, including elements like first name, phone number formatting, and so on, into the specific formats required by individual customers. The transformed data is then tailored to match the formats required by their downstream databases. In cases where the confidence score is low or in industries subject to stringent regulations, the form data may be sent to a human-in-the-loop review. These automated stages can be used together or separately, resulting in significant cost reductions, elimination of manual effort, and enhancement of the outcomes of document processing for your business.
AWS architecture
The following figure illustrates the extended architecture of the sample system and explains how you can use AWS services to integrate the end-to-end process.
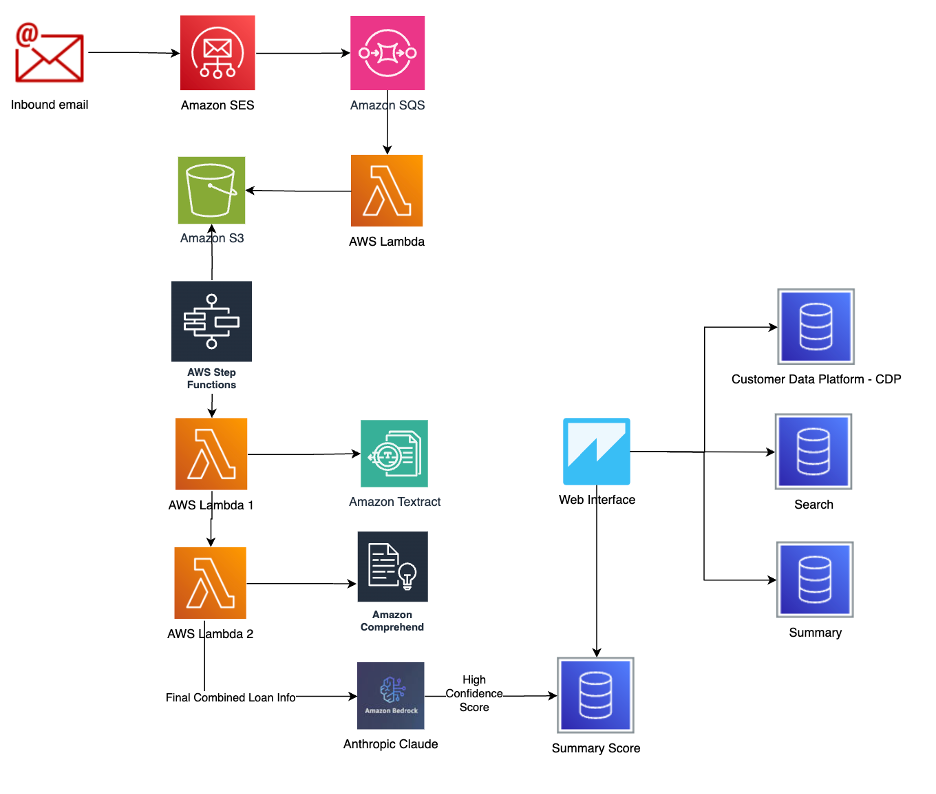
After the inbound email attachments are received and input documents are stored securely, AWS document processing services and FMs assist with the extraction and summarization in the desired format:
- Amazon Simple Storage Service (Amazon S3) stores documents in various format files, originated from physical or digital mailrooms, email attachments, or user uploads from web or mobile apps, allowing for efficient processing and scalability.
- Amazon Textract uses the power of NLP and other ML advancements cultivated over the years, enabling capabilities beyond conventional OCR technologies. Amazon Textract automatically extracts printed text, handwriting, layout elements, and other data such as key-value pairs and tabular information from any document or image.
- Amazon Comprehend can automatically classify and extract insights from text, which also provides NLP capabilities. It has pre-trained models that identify entities such as places, people, brands, or events; determine the language of the text; extract key phrases; understand how positive or negative the sentiment of text is; and automatically organize a collection of text files by topic.
- Amazon Bedrock is an enterprise cloud platform by AWS that provides a straightforward way to build and scale generative AI applications with FMs. It provides the necessary tools and infrastructure to deploy, monitor, scale, and govern AI/ML models effortlessly and cost-effectively. You can then have natural conversations with LLM models available in Amazon Bedrock to get insights from the vectorized data.
Our GitHub repo demonstrates how to combine Amazon Textract and LangChain to extract data from documents and use generative AI within different stages of IDP. These samples demonstrate using various LLMs.
Prerequisites
Before you start developing the document workflow, you must complete a few prerequisite steps. Refer to the GitHub repo for details on how you can integrate Amazon Textract with LangChain as a document loader to extract data from documents and use generative AI capabilities within the various IDP phases. The following imports are specific to document extraction from email:
Read emails and attachments
The configuration of UnstructuredEmailLoader is explained in the following code, which also summarizes the email content:
Clean up
Follow the cleanup steps specified in the GitHub repo to clean up your resources.
Conclusion
In this post, we explained how to streamline financial workflows with generative AI for email automation, including extracting data from email attachments, classifying documents, and summarizing and processing documents with IDP to derive insights. By examining the various stages of the IDP pipeline, you can enhance your own IDP pipeline with LLM workflows.
To expand this solution, consider the following:
- Use Retrieval Augmented Generation (RAG) correlation of personalized data in your LLM
- Keep summarized data private and accept existing data sources as augmented inputs to your desired decision outcome
To learn more, refer to the following resources:
About the Author
 Hariharan Nammalvar is a Solutions Architect at AWS, technology professional with 20+ years of experience. He has a proven track record of designing and implementing innovative solutions that solve complex business challenges. He has worked with a wide range of industries, different customer domain helped them to leverage machine learning and AI to streamline operations, improve efficiency, and enhance customer experiences.
Hariharan Nammalvar is a Solutions Architect at AWS, technology professional with 20+ years of experience. He has a proven track record of designing and implementing innovative solutions that solve complex business challenges. He has worked with a wide range of industries, different customer domain helped them to leverage machine learning and AI to streamline operations, improve efficiency, and enhance customer experiences.
 Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and Serverless Platform. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and Serverless Platform. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.


