Use modular architecture for flexible and extensible RAG-based generative AI solutions

Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model (LLM). It references an authoritative knowledge base outside of its training data sources before generating a response. A RAG-based solution lets organizations jumpstart generative artificial intelligence (AI) applications with faster and more cost-effective ways to inject fresh, trusted data into foundation models (FMs), making generative AI easier for businesses to onboard. It can further integrate individual data with the extensive general knowledge of the FM to personalize chatbot interactions.
You can utilize RAG to reduce hallucinations and answer meaningful business questions with your own proprietary data and business context. With RAG, LLMs can gain deep understanding into specific areas without having to be retrained, which makes it efficient and cost-effective to keep LLMs current, relevant, accurate, and helpful in many different situations. With the benefits mentioned above, RAG architecture applications are very common in intelligent search engines and chatbots. Generative AI is an area of active research that produces frequent new findings that lead to increased capabilities in new models, as well as new methods to run and maintain existing models more efficiently. This offers value for generative AI solutions that have a flexible architecture because the same production workload will become cheaper and faster to run, and the same workload can be updated to achieve greater accuracy and capabilities.
In this post, we cover an Amazon Web Services (AWS) Cloud infrastructure with a modular architecture that enables you to explore and take advantage of the benefits from different RAG-based generative AI resources in a flexible way. This solution provides the following benefits with faster time-to-market and shorter development cycle:
- Optimize search relevance through generative AI models that understand context and user intent.
- Plug in different vector stores to balance cost, performance, and accuracy.
- Adopt an extensible platform to easily swap AI services as new innovations emerge.
- Use containers and serverless to enable rapid experimentation.
Several elements can contribute to the overall accuracy and performance of the final response from the LLM in a RAG architecture. Since all data (including text, audio, images, or video) needs to be converted into embedding vectors for generative models to interact with it, vector databases play an essential role in solutions powered by generative AI. Traditional databases such as OpenSearch and PostgreSQL have added features to accomplish this. There is also a range of open source dedicated vector databases, such as ChromaDB and Milvus. Having an architecture that can integrate with different options means the solutions can be serverless, in-memory, fully managed, or have dynamic segment placement. These choices can be driven by answers to questions such as how often the new data is added, how many queries are submitted per minute, and whether the submitted queries are largely similar. Therefore, it is crucial to have a flexible architecture that evolves with data and business requirements.
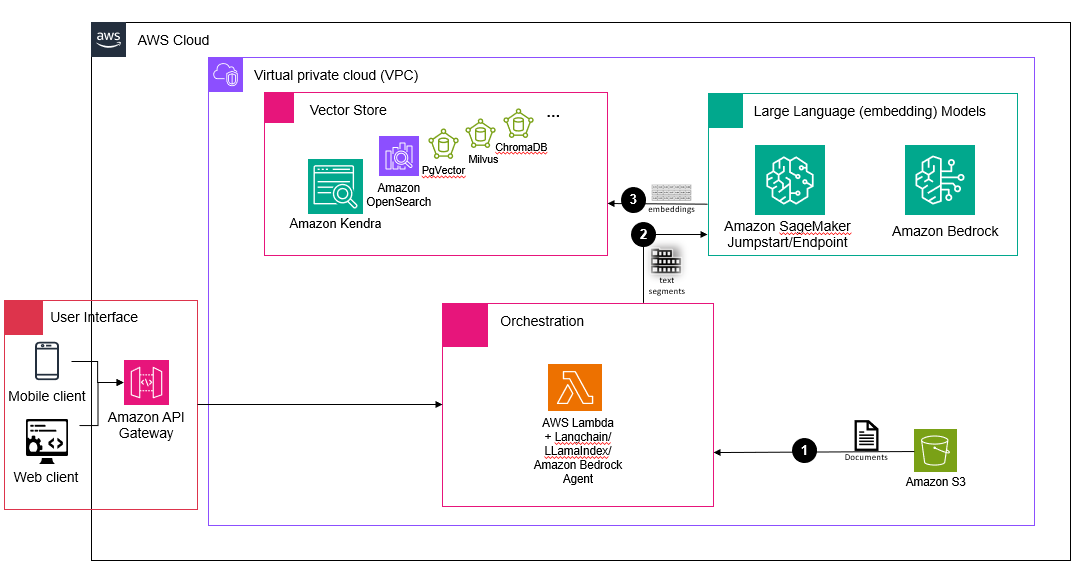
Figure 1. Architecture diagram of loading data into the vector store. The major components are vector store options including Amazon Kendra, Amazon OpenSearch and other open source options, LLM models hosted on Amazon SageMaker Jumpstart/Endpoint or Amazon Bedrock, orchestration components including AWS Lambda and Amazon Bedrock agent, storage component of Amazon S3, and the user interface of Amazon API Gateway.
As illustrated in Figure 1, the overall architecture has four modules: a user interface module that interacts with end users through Amazon API gateway (API gateway); an orchestration module that interacts with various resources to ensure that the data ingestion, prompting, and response generation process flows smoothly; the embeddings module that provides access to various foundation models; and the vector store module that takes care of storing embedded data and performing vector search.
The steps demonstrate the flow of loading data into the vector store:
- Initially, documents stored in Amazon Simple Storage Service (Amazon S3) buckets are processed by AWS Lambda functions for splitting and chunking (this step is not needed for Amazon Kendra).
- Text segments are fed into the embedding model to be converted into embeddings.
- Embeddings are then stored and indexed in the vector database of choice.
The following Figure 2 depicts the steps of generating a response with a prompt.
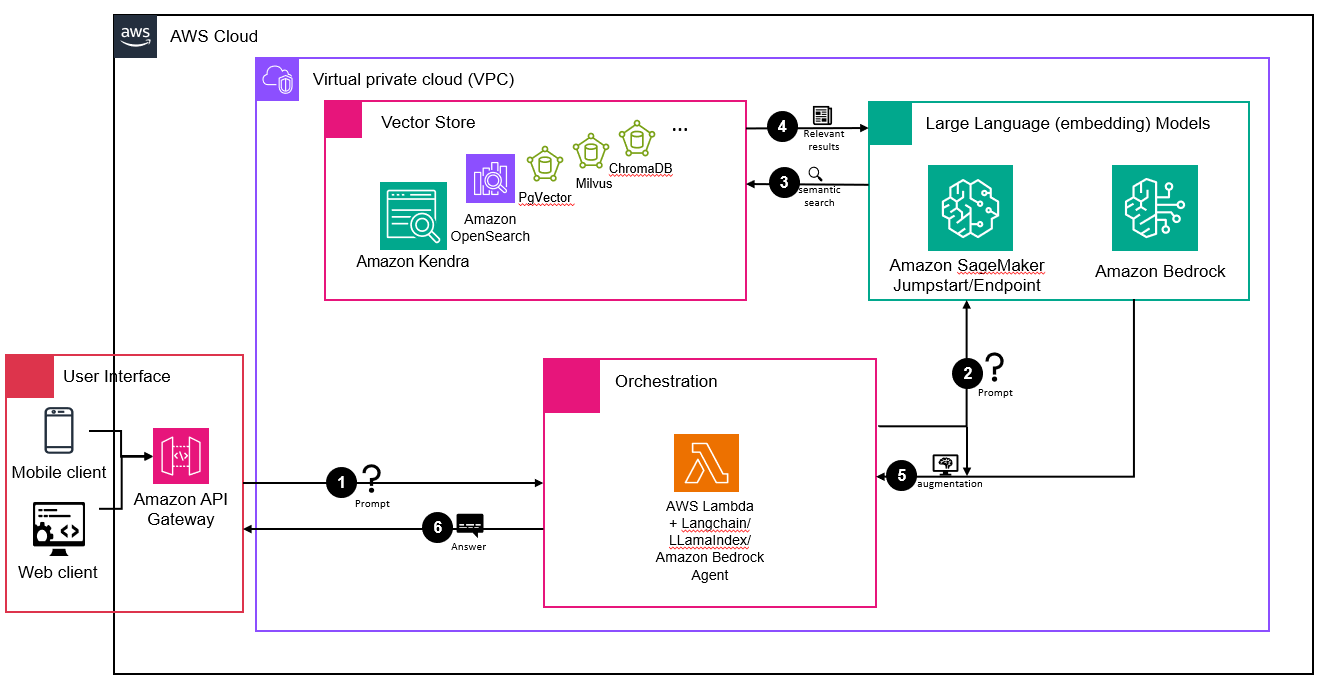
Figure 2. Architecture diagram of generating a response with a prompt. The major components are vector store options including Amazon Kendra, Amazon OpenSearch and other open source options, LLM models hosted on Amazon SageMaker Jumpstart/Endpoint or Amazon Bedrock, orchestration components including AWS Lambda and Amazon Bedrock agent, storage component of Amazon S3, and the user interface of Amazon API Gateway.
- The user submits a prompt.
- The prompt is delivered to an embedding model.
- The embedding model converts the prompt into a vector for semantic search against the documents stored in the vector database.
- The most relevant results are returned to the LLM.
- The LLM generates the answer by considering the most similar results and the initial prompts.
- The generated answer is then delivered back to the user.
This modular cloud architecture infrastructure enables the evaluation of vector stores, generative AI models, and more, using different evaluation metrics to optimize the architecture based on domain-specific requirements such as performance, cost, and accuracy. The modular architecture enables building an extensible generative AI solution platform harnessing AWS serverless and containers. It provides various benefits:
- Modularity and scalability – The modular nature of RAG architecture and the use of infrastructure as code (IaC) make it easy to add or remove AWS services as needed. With AWS managed services, this architecture helps you handle increasing traffic and data demands automatically and efficiently, without provision ahead of time.
- Flexibility and agility – Modular RAG architecture allows you to deploy new technologies and services more quickly and easily without having to completely revamp the cloud architecture framework. It enables you to be more agile in responding to changing market demands and customer needs. This can help you to quickly test out new services and solutions and adapt to changing market conditions.
- Adapting to future trending – The modular architecture separates orchestration, generative AI models, and vector store. Individually, these three modules are all areas of active research and improvement. For generative models, the emergence of mixture-of-expert architecture, 1-bit model weights, and improved chipset means that more capable models will likely run faster with higher accuracy, efficiency, and throughput in the future. Vector databases are also evolving as more of them become serverless capable, vector searches become optimized, and more security and failover features are introduced. Tools such as Agents for Amazon Bedrock and LangChain are building new features to orchestrate data ingestion intelligently and execute more multistep downstream tasks. The modular architecture thus allows for quick experimentation with each module to evaluate the performance of new features while holding all other variables constant. It also encourages strong versioning and reproducibility, thus improving the transparency of both the development and production process.
The pace of evolution of generative AI is taking place at an unprecedented rate. There are new FMs and vector stores emerging every week. Enterprises are eager to select the best generative AI configuration, and evaluate the different options based on factors including accuracy and reliability, explanation and source attribution, integration requirements, response time, deployment speed, integration, management efforts, and cost. From these benefits of the AWS modular architecture, your RAG solutions can optimize the solution using the best fit-for-purpose LLM and vector store for your business use case, along with promoting reuse across different solutions within your organization in conversation chatbots, searches, and more.
For cloud-based workloads with strict compliance requirements, this modular AWS Cloud architecture infrastructure offers a range of service options that can satisfy the rigorous standards, such as in AWS GovCloud (US) Regions or the IL4, IL5 and IL6 networks. This empowers public sector organizations to harness the power of generative AI resources with flexibility and agility, while ensuring the levels of security and compliance.
Learn more:




{kind=link}